AI 辅助数据分析:从表格到可复用流程
到这一节,产品开始不只是“页面”
很多人做完前两节之后,会自然地把“做产品”理解成:
做一个页面,做一个小工具,做一个链接。
这当然没错。
但在真实医疗工作里,很多高价值场景的核心问题,根本不是页面,而是:
- 数据太乱
- 表格太杂
- 每次都要重复分析
- 结果要重复整理
所以这一节的重点,是让你开始意识到:
产品不只是界面,很多时候更重要的是背后的流程。
先认识“表格数据”这件事
在前面几级课里,你已经很熟悉文本、资料、知识库、提示词了。
到了这一节,第一次要明确区分:
文本资料 和 结构化数据 不是一回事。
这几个词先不要陌生
| 名词 | 你可以怎么理解 |
|---|---|
| Excel | 最常见的表格文件 |
| CSV | 一种更简单、更适合程序处理的表格格式 |
| 表头 | 每一列代表什么 |
| 行 / 列 | 一行通常是一条记录,一列通常是一种字段 |
| 结构化数据 | 数据已经按固定字段整理好,不是散乱的自然语言 |
比如一张科室月报原始表:
| 日期 | 科室 | 出院人数 | 平均住院日 | 死亡人数 |
|---|---|---|---|---|
| 2026-01 | 呼吸科 | 125 | 8.2 | 3 |
这就是结构化数据。
它和你前面上传给 AI 读的一篇指南、一个 PDF、一个病例讨论文本,完全不是一种东西。
文本资料
- 指南、论文、病例讨论
- 更适合总结、解释、改写
- 重点是语义理解
结构化数据
- Excel、CSV、固定字段表格
- 更适合清洗、统计、画图、生成描述
- 重点是字段和格式一致

再认识一个词:数据字典
如果你后面真的要把分析做成流程,最好再知道一个概念:
数据字典,就是“每一列到底代表什么”的说明书。
比如:
sex是 0/1 还是 男/女outcome里 1 代表出院还是死亡scr的单位到底是 mg/dL 还是 umol/L
很多所谓“AI 分析错了”,其实不是 AI 不会算,而是字段含义一开始就没说清楚。
为什么这个区分很重要
因为 AI 面对这两类东西,擅长的帮助也不同:
- 面对文本资料,擅长总结、解释、改写、提炼
- 面对结构化数据,擅长清洗、整理、初步统计、生成图表和描述
所以这一节其实是在给你补上一个新视角:
AI 不只是“会聊天”,它还可以成为你的数据助理。
AI 处理数据,到底能帮你做什么
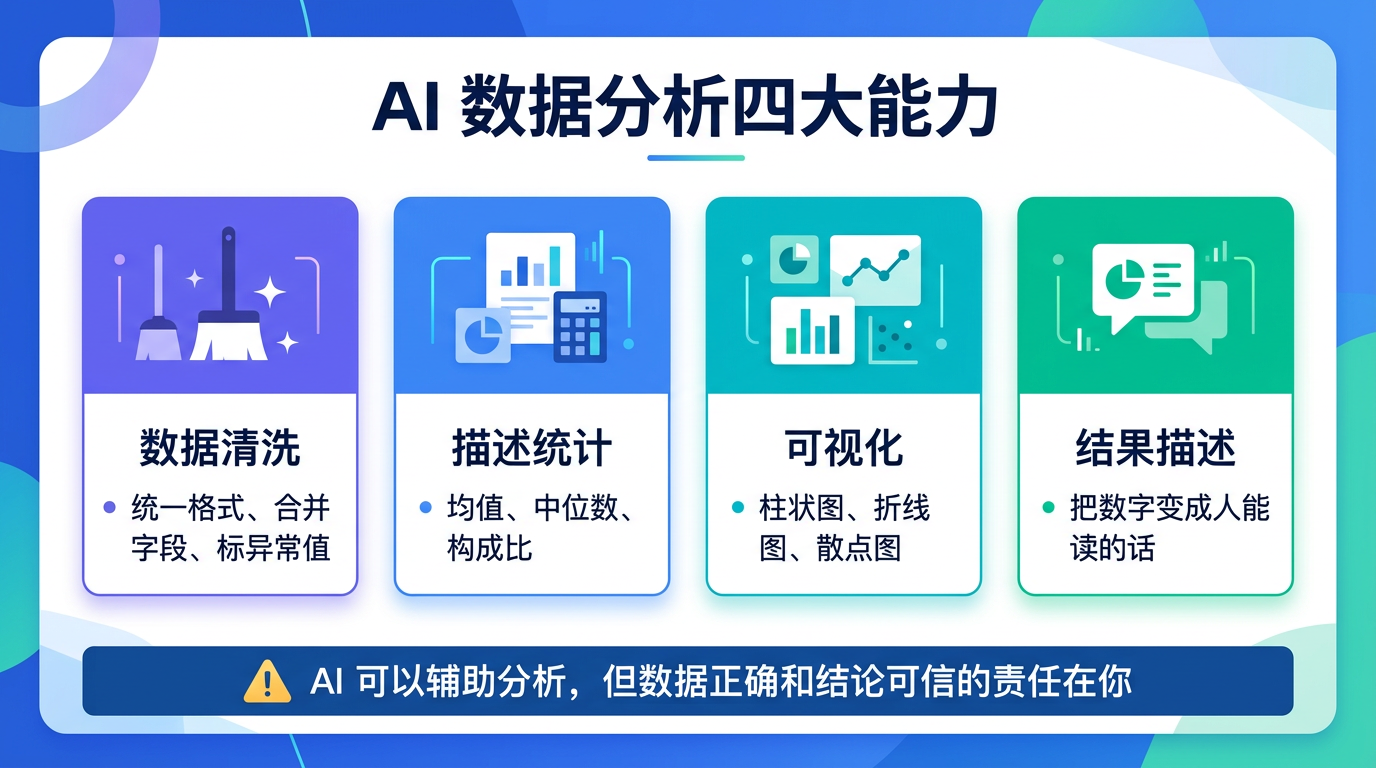
在医疗工作里,AI 对数据最常见的帮助主要有四类:
1. 数据清洗
把原本乱七八糟的数据整理成更规范的格式。
比如:
- 统一日期格式
- 合并同义字段
- 识别明显异常值
- 把空白和缺失标出来
2. 描述性统计
帮你快速做最基础的统计整理,比如:
- 均值
- 中位数
- 构成比
- 分组计数
3. 可视化
帮你生成更容易展示的图表,比如:
- 柱状图
- 折线图
- 饼图
- 散点图
4. 结果描述
帮你把“图和数字”变成一段人能看懂的话。
比如:
2026 年 1-3 月,呼吸科出院人数总体平稳,2 月略下降,平均住院日呈轻微下降趋势。
这类话,AI 很擅长写。
数据清洗
统一格式、识别异常、标出缺失,把乱表先收干净。
描述性统计
快速做均值、中位数、构成比和分组计数等基础统计。
可视化
把结果转成柱状图、折线图、饼图、散点图等更好展示的形式。
结果描述
把图和数字写成一段人能直接读懂的话,方便汇报和初稿整理。
但有一条底线不能丢
这里要和 L1 呼应一次:
AI 可以辅助分析,但不能替你承担“数据正确”和“结论可信”的责任。
也就是说:
- 它可以帮你算、帮你整理、帮你描述
- 但最后数字对不对、结论能不能写进正式报告,还是要你负责
路径一:先用对话式 AI 做一次性分析
这是最适合新手起步的路径。
适合什么场景
- 一次性的探索性分析
- 你想先看看数据大概有什么特征
- 你暂时还不确定值不值得做成工具
一个典型例子
你可以上传一份脱敏后的临床数据,然后说:
请根据这份数据生成一张 Table 1,列出基线特征,包括年龄、性别、BMI、主要合并症,并按住院结局分组比较。
AI 可能会帮你先做出一个结构化结果,再帮你写出简短说明。
如果你愿意再往前走一步,还可以把任务说得更完整一点:
先检查缺失值和异常值;再按住院结局分组生成 Table 1;最后给我一段 150 字以内的中文结果描述,并单独列出需要人工复核的地方。
这样做的好处是,AI 不只是“算一下”,而是开始帮你搭一个更像正式工作的流程。
| 路径一:一次性分析的优势 | 路径一:一次性分析的局限 |
|---|---|
| 快 | 更像临时请一个助理帮你看一遍 |
| 上手门槛低 | 下次换一份文件,你还得重新来 |
| 适合先摸清问题 | 流程不一定稳定 |
所以这种方式很适合“探索”,但不一定适合“长期重复执行”。
路径二:把重复分析做成一个小工具
如果你发现某类分析是每个月都要做、每次步骤差不多,那就值得往前走一步。
一个很典型的场景
比如:
- 每个月都要做科室月报
- 每次都要导入数据
- 每次都要出图
- 每次都要写一段摘要
这就很适合做成一个“月报自动生成器”。
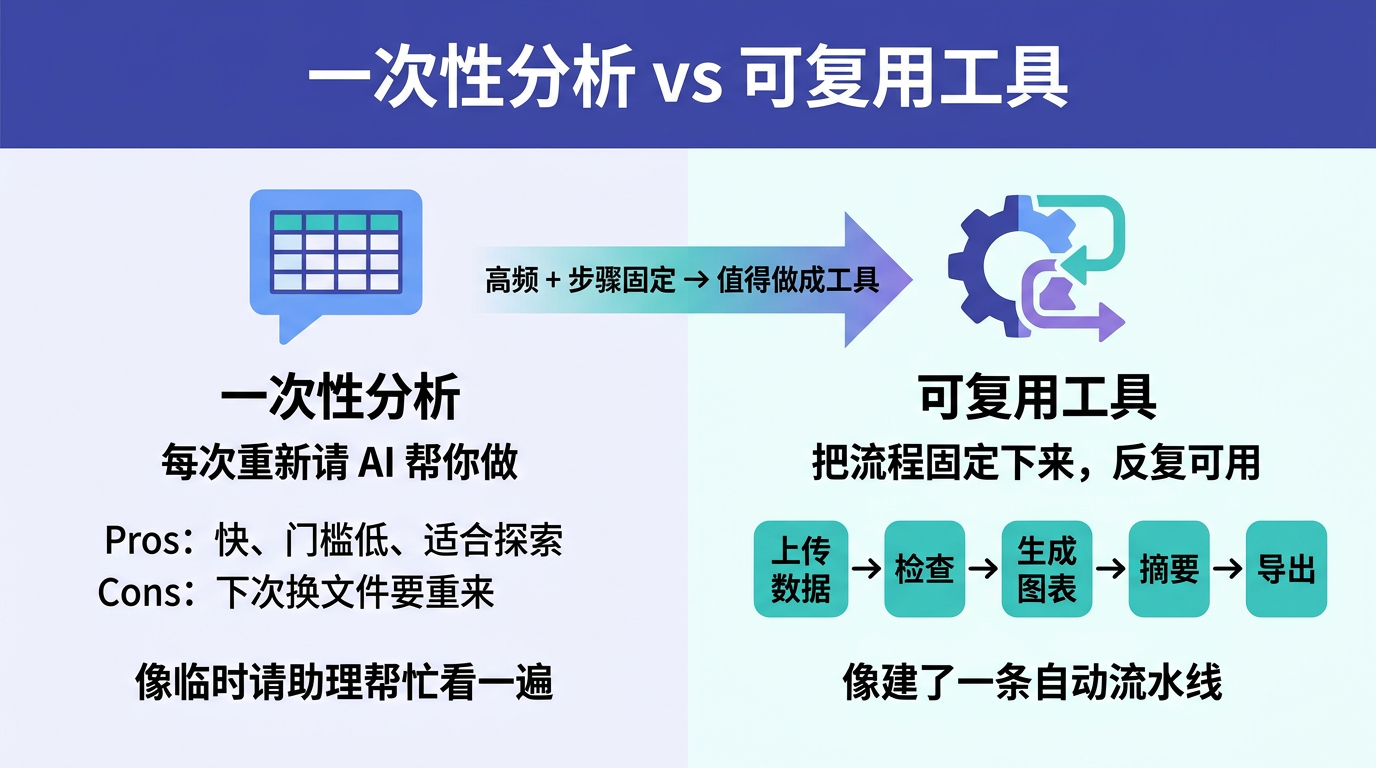
它的最小流程其实可以非常朴素:
上传本月数据
↓
检查缺失和异常
↓
生成固定图表
↓
生成摘要草稿
↓
人工复核后导出
你可以理解成:
- 前一种方式:每次都重新请 AI 帮你做
- 这一种方式:把流程固定下来,让它以后反复可用
这就是“工具思维”真正开始介入的地方。
为什么这一步值得做
因为同一类分析会反复发生。
如果一个任务:
- 高频
- 步骤相对固定
- 输出有模板
那你每次重新对话做,其实就开始浪费时间了。
把它做成工具,才更像产品。
什么时候值得工具化
- 任务高频重复发生
- 步骤已经相对固定
- 输出格式有稳定模板
- 你希望下个月继续复用,而不是重新从头对话
一次性分析
- 适合先探索
- 上手快
- 每次都要重新来一遍
可复用工具
- 适合高频任务
- 步骤稳定
- 下个月还能继续跑
数据安全:这一节的风险观要比前两节更强
前两节主要做的是页面和小工具,很多时候风险还相对可控。
到了数据分析,这一节必须更严肃一点。
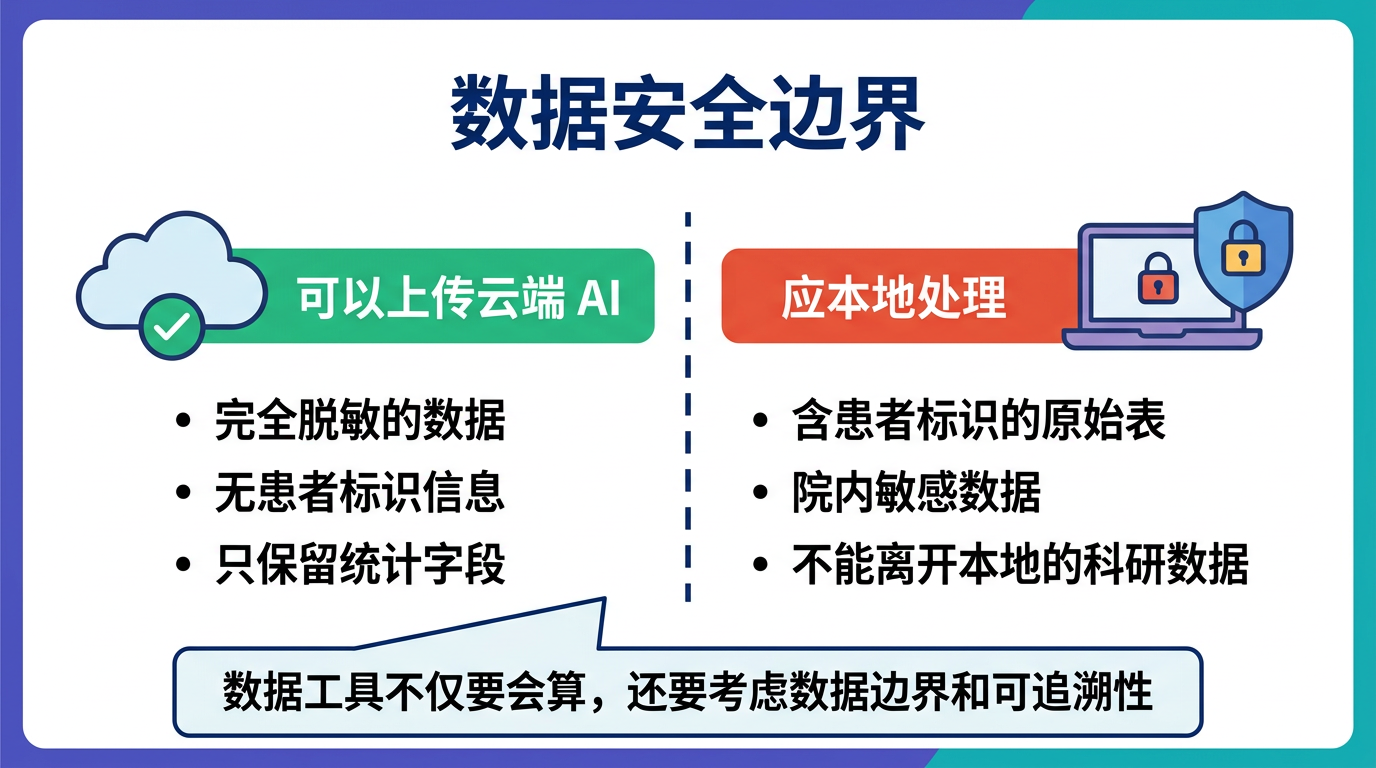
什么数据可以上传到云端 AI
一般来说,前提是:
完全脱敏,并且不包含可识别患者信息。
比如:
- 已经去掉姓名、住院号、身份证号
- 只保留统计需要的字段
- 没有明显可回溯到个人的信息
什么数据更适合本地处理
以下这类数据要更谨慎:
- 含患者标识信息的原始表
- 需要严格院内处理的敏感数据
- 不能离开本地环境的科研原始数据
这时候就更适合:
- 在本地环境处理
- 用本地模型或院内可控方案
- 至少把最敏感的数据处理留在本地
这节课真正想埋下的工程化意识
数据工具不仅要会算,还要考虑数据边界、可追溯性和重复运行。
这和做一个“能点一下出结果”的页面是不同层级的问题。
数据边界要先分清
- 完全脱敏、不可回溯到个人的数据,才更适合上传到云端 AI 做辅助分析
- 含患者标识信息的原始表、严格院内处理的数据,更适合本地或院内可控环境处理
- 不是 AI 不会算,而是数据边界决定了你能不能安全地用它来算
第三节想让你建立的,是“流程价值感”
到了这里,你会慢慢发现:
前两节更像是在做“看得见的产品入口”,
这一节开始在做“真正省事的底层流程”。
这一步非常重要,因为很多高频工具的价值,最后不是体现在“页面多漂亮”,而是体现在:
- 能不能减少重复劳动
- 能不能让结果更稳定
- 能不能让下个月继续用
本节小结
| 概念 | 一句话 |
|---|---|
| 结构化数据 | 按固定字段整理好的数据,不是自然语言文本 |
| Excel / CSV | 常见的表格数据载体 |
| 一次性分析 | 适合探索,不一定适合长期复用 |
| 可复用流程 | 同一类分析反复发生时,更值得做成工具 |
| 数据边界 | AI 能帮你做很多事,但敏感数据处理必须更谨慎 |
本节带走:
- 一次真实的数据分析体验
- 一次把“重复分析”往工具化推进的尝试
- 一层新的判断:产品不只是页面,很多时候更重要的是流程