自动化工作流:让 AI 定时帮你干活
你应该已经开始有这种冲动了
学完 L3 前四节之后,很多人都会冒出同一个念头:
既然我已经能让 AI 按规则回答、查外部资料、翻内部资料、还封装成智能体了,那能不能让它别等我开口,自己按时把事做了?
比如:
- 每周一早上自动追踪某个病种的新文献
- 每个月自动整理一次科室质控数据摘要
- 每次开组会前自动把上周的新进展汇总成一页简报
- 每天早上自动检查某个网页有没有更新新的指南或通知
这就是 L3 最后一节要解决的问题:自动化工作流。
如果前四节解决的是"让 AI 更会干活",那这一节解决的是"让 AI 到点就开工"。
什么叫“自动化工作流”?
先讲最朴素的定义
自动化工作流,指的是:
一件原本需要你手动重复做的事情,被拆成固定步骤后,交给系统自动触发、自动处理、自动输出。
你可以把它理解成:
到了某个时间,或者发生了某个条件,系统自动启动一串你事先设计好的动作,最后把结果送到指定地方。
工作流,不等于“很高级的系统”
很多人一听“工作流”,就觉得那一定是企业级平台、IT 部门、流程引擎,离自己很远。
其实不然。
你每天手工做的很多事,本质上都是工作流,只是现在是靠你自己在脑子里跑这串步骤:
周一到办公室
→ 打开 PubMed
→ 搜索关键词
→ 挑 5 篇值得看的文章
→ 粘到 AI 里生成摘要
→ 复制到 Word/飞书
→ 发给组里
这一串动作,就是一个工作流。
自动化要做的,不是发明一件新事,而是把你原来手工做的事情拆出来,交给系统执行。
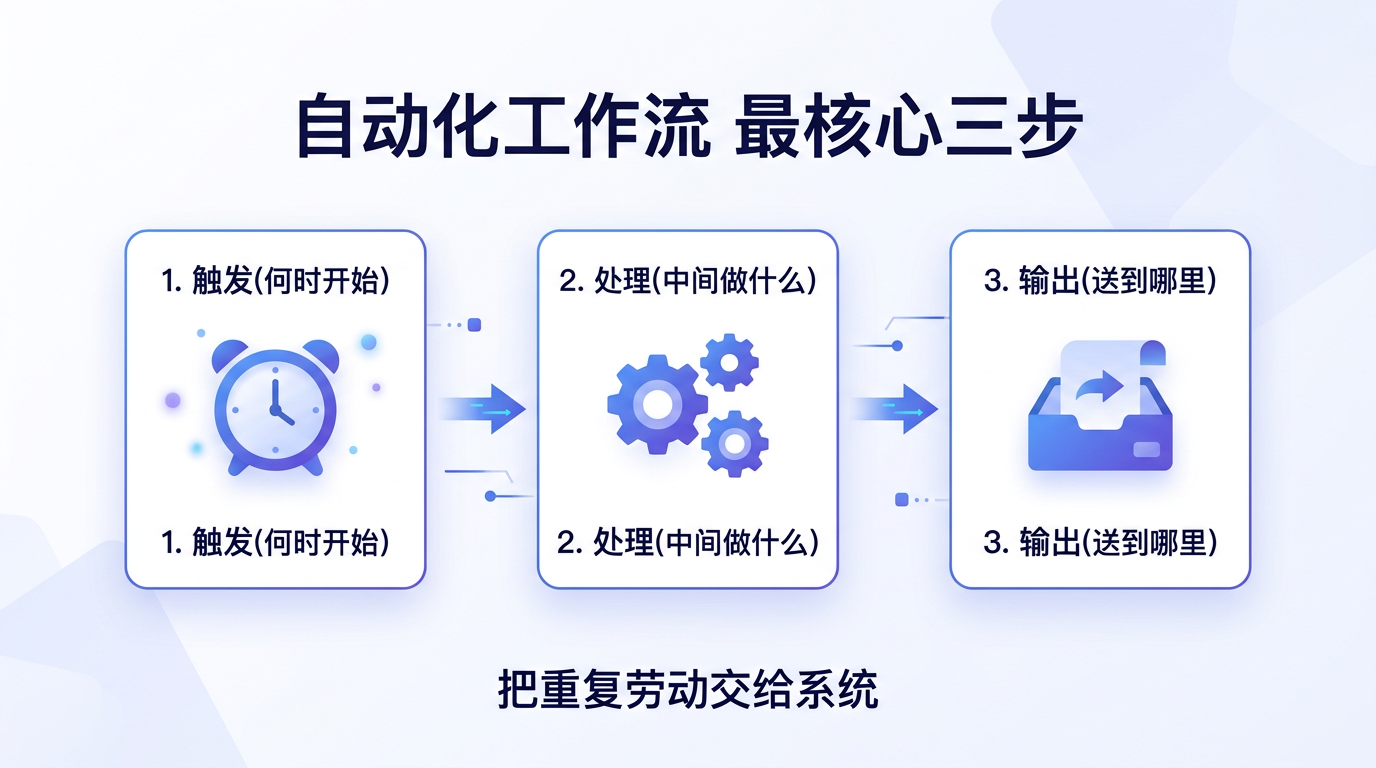
最核心的三步
这一节最重要的基础概念,就是这三个词:
| 环节 | 它在问什么 | 例子 |
|---|---|---|
| 触发(Trigger) | 什么时候开始? | 每周一早上 8 点;有新邮件时;某个表单被提交时 |
| 处理(Process) | 中间做什么? | 检索文献、摘要、分类、翻译、生成表格 |
| 输出(Output) | 最后送到哪? | 飞书群、邮箱、Markdown 文档、Excel、Notion 页面 |
只要你能把一件事说清楚这三步,你就已经走上自动化思维了。
自动化和“手动问 AI”到底差在哪?
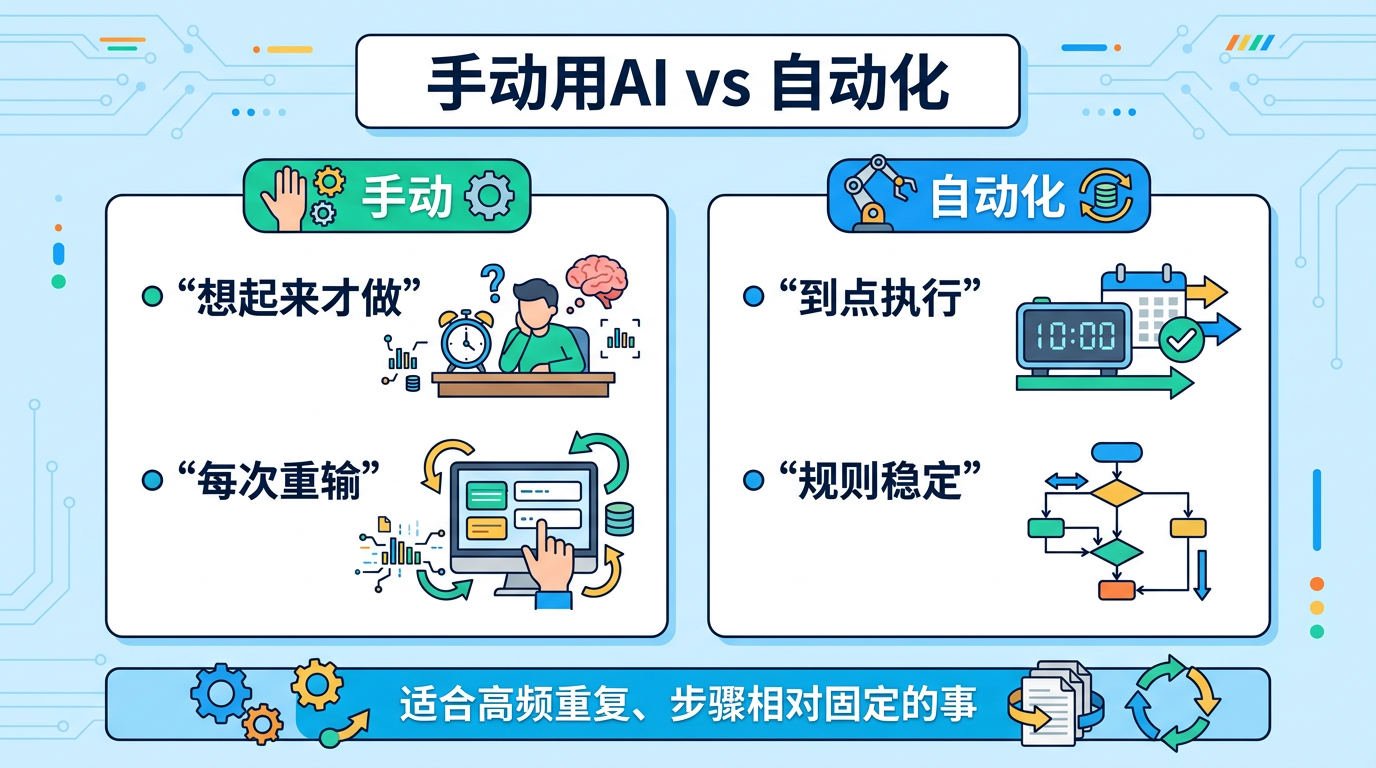
| 手动用 AI | 自动化工作流 | |
|---|---|---|
| 启动方式 | 你想起来才去做 | 到点自动做 / 条件满足自动做 |
| 稳定性 | 取决于你是否记得、是否有空 | 规则设好后稳定执行 |
| 适合场景 | 一次性问题、探索性问题 | 重复性高、步骤相对固定的问题 |
| 你花时间在哪 | 每次重新打开、重新输入 | 前期设计流程,后期主要审核 |
所以自动化最适合的,不是"最复杂"的任务,而是那些你会重复做很多遍、每次又差不多的任务。
什么样的事情适合自动化?
这是决定你会不会白费力气的关键问题。
适合自动化的任务,一般有四个特征
| 特征 | 为什么重要 |
|---|---|
| 高频重复 | 做一次不值得,做很多次才值得自动化 |
| 输入相对固定 | 如果每次输入都完全不同,流程就很难固化 |
| 输出有模板 | 结果格式越固定,越适合自动化 |
| 风险可控 | 低风险信息处理,比高风险临床决策更适合 |
医疗场景里特别适合的例子
- 每周文献追踪
- 晨会前的资料整理
- 会议纪要自动总结
- 定期生成科室周报/月报
- 患者宣教材料模板化生成
- 某类病例资料的结构化整理
一开始不适合全自动的例子
- 最终诊断决策
- 处方开具
- 与患者直接沟通的最终回复
- 高风险、不允许出错的外发内容
一句话:
优先自动化“搜、整、转、推”这些流程,不要一开始就自动化“判、签、发”这些责任环节。
先别急着上工具,先学会“拆流程”
很多人做自动化失败,不是工具不会用,而是根本没把任务拆清楚。
一个常见错误
“我想做一个自动追踪文献并且自动总结并且自动推送并且自动给出临床建议的系统。”
这句话听起来很厉害,但几乎没法直接落地。
更好的说法应该是:
- 触发:每周一早上 8 点
- 输入:检索关键词
CKD AND SGLT2 inhibitor - 处理 1:拉取最近 7 天的新文献
- 处理 2:筛出临床研究和指南
- 处理 3:生成中文摘要,每篇 100 字
- 输出:发到飞书群,并保存成一份 Markdown 文档
这样就清楚多了。
一个实用模板
你可以用下面这个模板,先把任何一个自动化任务写清楚:
我要自动化的事情:
触发条件:
输入从哪里来:
中间需要做哪几步:
最终产出是什么:
要发到哪里:
哪些地方必须人工审核:
只要你能填完这六行,后面选工具就简单很多。
自动化不是“完全无人值守”,而是“人在回路”
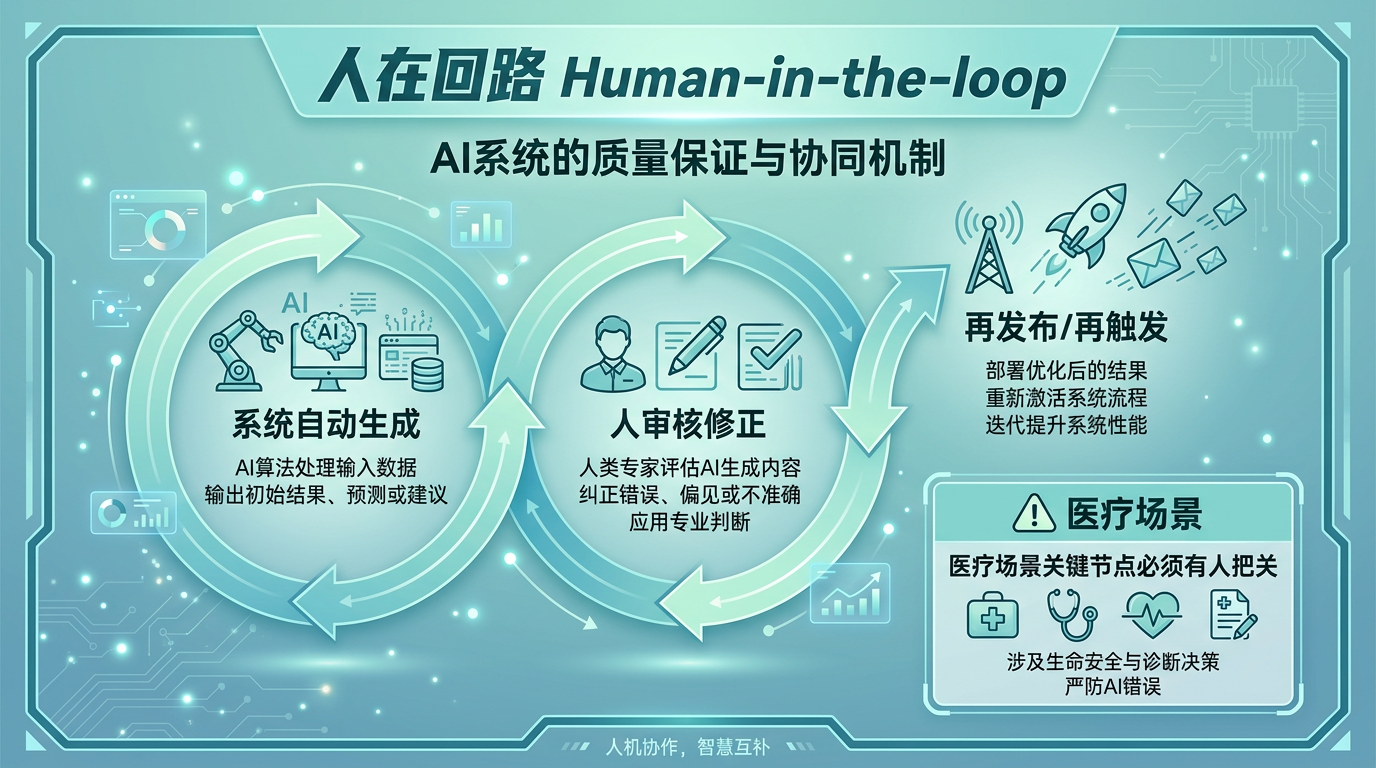
这是整节课里最重要的安全观念。
很多人一提自动化,就会脑补成:
AI 自动干完,我再也不用管了。
这在医疗场景里非常危险。
什么叫“人在回路”
意思是:
流程可以自动跑,但关键节点要保留人的审核、确认或兜底。
比如:
- 自动检索文献:可以全自动
- 自动生成摘要:可以全自动
- 自动推送给科室群:最好先人工抽查
- 自动生成患者宣教草稿:可以
- 自动直接发给患者:不建议
一张特别重要的表
| 环节 | 适不适合全自动 | 原因 |
|---|---|---|
| 信息收集 | 很适合 | 低风险、高重复 |
| 格式转换 | 很适合 | 结构明确、风险低 |
| 初稿生成 | 适合 | 但最好人工过一遍 |
| 临床判断 | 不适合 | 责任和风险太高 |
| 对外正式发布 | 谨慎 | 需人工审核 |
自动化的是流程,不是责任。 这句话一定要记住。
常见平台和工具:该怎么选?
这节课不打算把你变成自动化平台专家,我们只讲够用的。
第一类:AI 工作流平台
适合想用拖拽方式把 AI 放进流程里的人。
| 工具 | 适合谁 | 特点 |
|---|---|---|
| 扣子(Coze)工作流 | 想快速上手的人 | 可视化拖拽,AI 节点友好 |
| Dify | 想更系统一点的人 | 知识库、工作流、应用结合更完整 |
第二类:办公自动化平台
适合结果要落到日常办公工具里的人。
| 工具 | 适合谁 | 特点 |
|---|---|---|
| 飞书自动化 | 飞书重度用户 | 适合推消息、写表格、接表单 |
| 钉钉自动化 | 钉钉办公团队 | 适合和日常审批、通知打通 |
第三类:更前沿的自主执行工具
适合想体验“AI 不只是按固定节点跑,而是更主动地连续执行任务”的人。
| 工具 | 特点 |
|---|---|
| OpenClaw / Claw | 更像一个长期驻留的个人助理,可以连续执行多步动作 |
先怎么选?
如果你是第一次接触自动化:
- 先从可视化工作流平台开始
- 先做一个简单、稳定、低风险的流程
- 不要一上来就追求最酷的前沿工具
工具不是重点,流程拆得清不清楚才是重点。
一个完整案例:每周文献追踪工作流
这一节我们用一个最适合教学的案例,把自动化跑通一遍。
为什么选这个案例
因为它具备几个优点:
- 高频
- 有明确触发时间
- 步骤清楚
- 风险低
- 很容易体现“自动化到底省了什么”
这个工作流要做什么
目标是:
每周一上午 8 点,自动检索某个主题最近 7 天的新文献,生成中文摘要,按相关性排序,发到飞书群,同时保存成一份 Markdown 文档。
是不是很像一个真实会有人用的东西?这就是好案例。
第一步:定义触发条件
这一步最简单,也最容易懂。
触发方式通常有三种
| 触发方式 | 例子 | 适合什么场景 |
|---|---|---|
| 定时触发 | 每周一 8:00 | 周报、月报、定期追踪 |
| 事件触发 | 有新表单提交 | 入组、登记、数据收集 |
| 条件触发 | 某网页有更新 | 监测指南更新、政策更新 |
这节课的案例用的是最容易理解也最常用的一种:定时触发。
设定:
每周一上午 8 点执行一次
这样周一上班前,组里就能看到整理好的内容。
第二步:定义输入
很多人自动化做不起来,是因为输入源没想清楚。
在这个案例里,输入包括两部分:
- 检索关键词
- 检索时间范围
比如:
- 检索词:
CKD AND SGLT2 inhibitor - 时间范围:最近 7 天
输入越固定,自动化越稳
如果你的关键词每次都完全不同,自动化就不一定值得做。
但如果你每周都在关注某个固定方向,比如:
- 糖尿病并发症
- 肿瘤免疫治疗
- ICU 抗感染
- 骨质疏松
那就非常适合做成自动化。
第三步:定义中间处理节点
这一部分,就是工作流真正的“干活环节”。
一个典型的文献追踪流程可以拆成这样
- 检索最近 7 天新文献
- 过滤掉明显不相关的内容
- 保留指南、临床试验、重要综述
- 用 AI 生成中文摘要
- 按临床相关性排序
- 生成一个统一格式的输出
把“AI”放在哪一步最合适?
这也是通识课里必须讲清楚的点。
很多人会误以为:
自动化 = 整个流程都交给 AI
其实不是。
更稳妥的思路是:
- 检索:让工具完成
- 筛选与总结:让 AI 完成
- 最终审核:人来做
也就是说,AI 在流程里通常是一个处理节点,而不是整个系统的全部。
第四步:定义输出
输出决定了这套流程最后有没有“落地”。
在这个案例里,我们有两个输出:
- 飞书群消息
- Markdown 文档归档
为什么要双输出
只发消息,不留档,过两天就找不到了。
只存文档,不主动推送,大家可能根本不会去看。
所以最实用的方式通常是:
- 一个主动推送
- 一个长期留档
这比只做其中一个都更有价值。
在平台上搭时,你会看到什么?
不同工具界面不一样,但大致都能抽象成下面这样:
[定时触发]
↓
[检索节点]
↓
[AI 摘要节点]
↓
[整理格式节点]
↓
[发送到飞书]
↓
[保存文档]
你可以把它理解成医院里的一张流程图:
- 什么时候开始
- 谁来处理
- 处理完交给谁
- 最后结果去哪
自动化平台做的,只是把这张流程图变成一个能运行的程序。
这套工作流到底替你省了什么?
假设以前你每周手工做一次,大概要花:
| 动作 | 大概耗时 |
|---|---|
| 检索文献 | 15 分钟 |
| 挑选值得看的文章 | 10 分钟 |
| 生成摘要 | 10 分钟 |
| 整理到飞书/文档 | 10 分钟 |
| 合计 | 45 分钟左右 |
如果做成自动化之后:
- 系统自动跑完:约 5-10 分钟后台执行
- 你需要做的:抽查和快速确认,5 分钟左右
每周省下来的不只是 30-40 分钟,更多是:
- 不容易漏做
- 不依赖你当时有没有空
- 内容格式更稳定
自动化的价值,很多时候不是“惊天动地的省时”,而是让本来经常掉地上的事,稳定落地。
什么时候该加“人工确认”节点?
这是把工作流做稳的关键。
一个很实用的设计原则
如果输出是:
- 发给自己看
- 发给小范围内部团队
- 用于初步筛选
可以更自动一些。
如果输出是:
- 发给患者
- 发到大群
- 进入正式报告
- 影响临床决策
就应该加一个人工确认节点。
怎么加?
很简单,流程里多放一步:
自动生成草稿
↓
发给你确认
↓
你点击“通过”
↓
再正式发出
这一步往往就是风险控制的分水岭。
一个前沿案例:为什么 OpenClaw / Claw 很适合讲在这里
前面我们讲的工作流,大多还是“节点式”的:
- 到点触发
- 执行几步
- 输出结果
这已经非常实用了。
但 2026 年很火的 OpenClaw / Claw,之所以值得在这一节提一下,是因为它代表了自动化的另一种方向:
不是只按固定节点跑,而是更像一个长期驻留、能连续执行多步任务的助手。
你可以怎么理解它
如果说传统工作流像:
你画好一条固定流水线,东西沿着流水线往前走
那 OpenClaw / Claw 更像:
你有一个住在电脑里的助理,你给它目标,它自己去分步执行、记录、继续跟进
这和你前面看过的 L2-番外|OpenClaw:全网都在“养龙虾” 是接得上的。
它为什么适合放在“自动化”这一节
因为它特别适合做这类任务:
- 定时检查某个网页有没有新内容
- 自动整理收件箱里的信息
- 连续打开多个页面抓取资料
- 把搜集到的内容汇总成文档
- 长期跟踪一个任务状态,而不是一次性回答完就结束
你会发现,这些都已经超出了“普通对话”的范畴,进入了“连续执行任务”的范畴。
但为什么不把整节课都讲成 Claw?
因为通识课最重要的,还是方法要稳定,工具可以更替。
今天最火的是 OpenClaw / Claw,明年可能是别的。
所以这节课的主干仍然应该是:
- 触发
- 处理
- 输出
- 人在回路
而 OpenClaw / Claw 适合作为一个前沿案例,让学员知道:
自动化不只是“到点跑个流程”,未来还会越来越像“养一个长期驻留、会持续做事的助手”。
如果想把 Claw 用进医疗场景,什么方向更靠谱?
这里一定要讲边界,不然大家会幻想它替自己值班。
比较靠谱的方向
- 自动跟踪某类公开网页更新
- 自动整理公开信息和文献链接
- 自动生成学习资料、晨会素材、周报草稿
- 自动做重复性信息搬运和格式整理
不靠谱或者高风险的方向
- 直接自动处理真实患者敏感信息
- 自动给患者发诊疗建议
- 自动完成高风险临床决策
也就是说:
Claw 适合“自动做事”,但在医疗场景里,仍应优先做低风险的信息处理工作。
常见翻车点
1. 选了一个根本不适合自动化的任务
如果每次都高度依赖临床判断,那就不该先做自动化。
2. 流程没拆清楚
只说“我想自动追踪文献”,但没说清楚:
- 什么时候触发
- 用什么关键词
- 输出去哪
这样的流程很难搭稳。
3. 一上来做太复杂
第一次就想接:
- 多个数据源
- 多个 AI 节点
- 多种输出渠道
- 审批流
最后很容易整个流程都跑不顺。
4. 没有人工兜底
流程是自动了,但一出错就直接发出去了,风险非常大。
5. 为了自动化而自动化
有些流程手工只要 3 分钟,自动化反而要花 3 小时搭建,那就不划算。
自动化的前提是:重复次数足够多,值得你前期投入。
怎么判断一个自动化值不值得做?
给你一个很实用的小公式:
值不值得自动化
= 单次节省时间 × 发生频率 × 稳定性收益
- 搭建和维护成本
比如:
- 每周都要做
- 每次要花 30 分钟
- 漏做会影响团队信息更新
这类事情就很值得做。
而如果:
- 两个月才做一次
- 每次 5 分钟
- 手工做也不麻烦
那就不值得优先自动化。
动手试一试
如果你想把这一节真正学会,建议你做一个最小工作流:
- 选一个高频、低风险、步骤固定的任务
- 用“触发-处理-输出-人工审核”模板写清楚
- 用扣子、Dify、飞书自动化中的任意一个平台搭起来
- 先跑通一个最小版本: - 一个触发 - 一个 AI 处理节点 - 一个输出渠道
- 再考虑进阶:
- 多个节点
- 多个数据源
-
OpenClaw / Claw这种更自主的执行方式
先跑通,再变强。
本节小结
| 概念 | 一句话 |
|---|---|
| 自动化工作流 | 把重复任务拆成触发、处理、输出,交给系统自动执行 |
| 最适合的场景 | 高频、低风险、输入相对固定、输出可模板化的任务 |
| 关键安全原则 | 自动化的是流程,不是责任;关键节点要有人在回路 |
| 典型案例 | 每周文献追踪、自动摘要、自动推送 |
| Claw 的意义 | 代表“更连续、更主动的自动执行”方向,但不应替代课程主干方法 |
本节带走:
- 一个能跑通的最小自动化工作流
- 一套判断标准:什么值得自动化,什么不该自动化
- 一个进阶视角:
OpenClaw / Claw不是这节课的重点,但它很好地展示了自动化未来会走向“长期驻留、连续执行”的方向
到这里,Level 3 的主线就完整了:
- L3-1:把提示词固化下来
- L3-2:让 AI 查完再答
- L3-3:让 AI 用你的资料回答
- L3-4:把能力封装成同事能用的智能体
- L3-5:让这套能力按时自动运行
这五节课加起来,你就不再只是“会用 AI 的人”,而是开始拥有一套自己的 AI 工作系统。