AI 除了聊天还能干什么?
你可能低估了 AI 的能力范围
大多数人对 AI 的印象还停留在"在对话框里打字问答"——输入一个问题,得到一段回答。这确实是最基础的使用方式,但如果你的认知止步于此,那你大概只用到了 AI 能力的 10%。
到 2026 年,AI 已经能做的事远超"聊天":它能看图、画图、听音频、生成语音、写代码、做网页原型、处理表格、自动执行多步骤任务。这些能力在医疗场景中都有实际应用。
本节目标
帮你建立一个"AI 能力全景图",知道 AI 现在到底能做哪些事。不求深入操作(那是 L2 的事),但你需要知道可能性在哪里。
多模态:不只是文字
"多模态"(Multimodal) 是一个听起来很学术的词,但含义很直白——AI 能处理多种类型的信息,不只是文字。
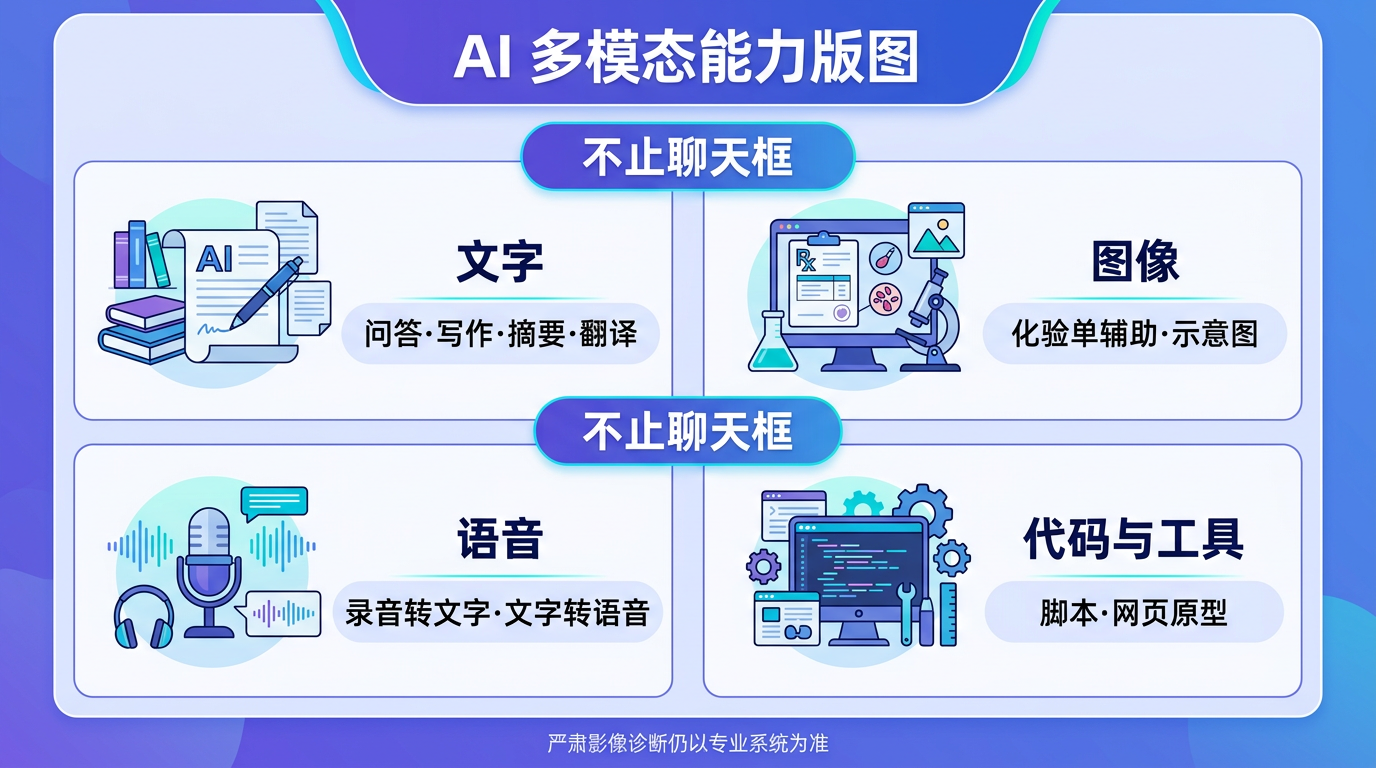
文字处理
这是最基础的能力,也是你在 L2 会重点学习的部分。AI 可以:
- 对话问答——你问它答,支持多轮上下文
- 写作——病历模板、出院小结、患教材料、科研论文初稿
- 翻译——中英医学文献互译,保留专业术语
- 摘要——长文献→核心要点,会议记录→行动清单
- 改写——学术语言→通俗表达(患教),口语化→正式文体
代码与小工具
这几年最被低估的一块能力,其实是写代码和做原型。你现在看到很多"一句话做网页""让 AI 帮我搭个表单或计算器",并不是噱头。
- 写脚本——批量整理表格、重命名文件、清洗文本数据
- 做网页原型——把一个教学页面、问卷页、患者教育页先快速搭出来
- 生成小工具——把固定流程做成计算器、表单、清单或半自动工作流
你不用把自己变成程序员,关键是知道:AI 现在已经不只是"帮你写字",也能帮你做工具。这也是后面 Level 4 会展开的方向。
图像:看 + 画
AI 处理图像有两个方向:理解图片和生成图片。
- 看:上传化验单照片 → AI 提取数据并结构化;拍摄手写笔记 → 转为结构化电子记录
- 画:生成患教插图、流程图、示意图;辅助制作医学科普图解
试一试:拍一张你手边的检验报告或处方,上传给支持图片识别的 AI 工具(如 ChatGPT、Kimi),看看它能识别出什么。
注意:AI 的"看图"能力用于辅助信息提取,不能替代专业的影像学诊断系统。
语音
- 语音转文字——会议录音 → 文字稿 → 会议纪要(讯飞听见、飞书妙记等工具已非常成熟)
- 文字转语音——将患教材料生成语音版,方便老年患者收听
视频
视频生成和视频理解都在快速进步,但在严肃医学内容里,视频仍然是最容易把"看起来很真"误当成"真的正确"的模态之一。它适合做演示素材、科普脚本草稿和非关键视觉内容,不适合直接承担严肃医学判断。
各角色的多模态应用场景
| 角色 | 文字 | 图像 | 语音 |
|---|---|---|---|
| 临床医生 | 病历润色、文献摘要、出院小结 | 化验单识别、患教插图 | 门诊录音转纪要 |
| 护理人员 | 护理记录模板、交班摘要 | 伤口照片记录辅助描述 | 床旁语音记录 |
| 药剂师 | 药物相互作用查询、用药指导 | 处方识别 | 用药交底录音整理 |
| 医学生 | 文献翻译、笔记整理、论文写作 | 手写笔记数字化 | 课堂录音→笔记 |
| 行政人员 | 会议纪要、公文起草、数据报告 | 表格截图→结构化数据 | 会议录音→行动清单 |
智能体 (Agent):从"你问它答"到"它替你干活"
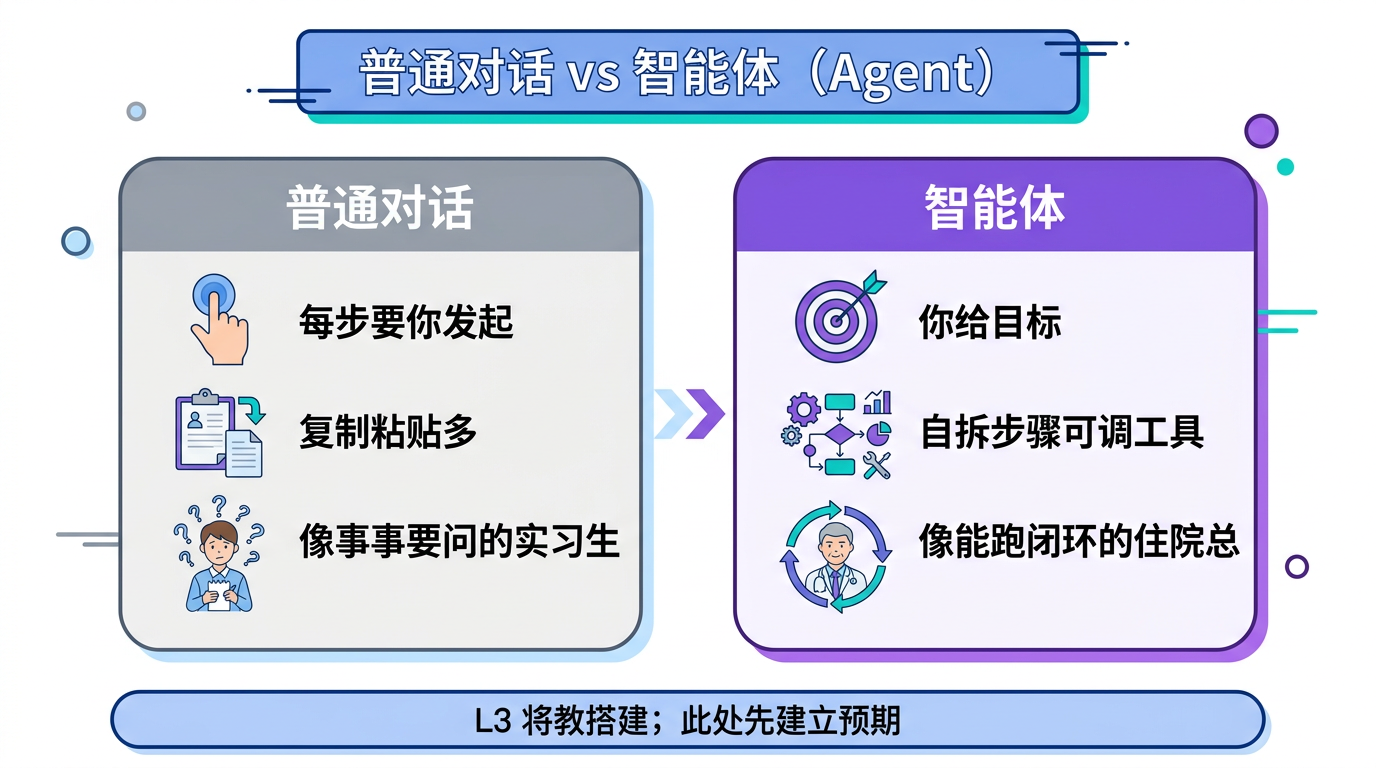
到目前为止,你对 AI 的使用模式可能都是这样的:
🔁 普通对话模式
你和 AI 一步一步交互,每一步都要你来发起。
🤖 智能体 (Agent) 模式
你给 AI 一个目标,它自己拆解任务、调用工具、逐步完成。
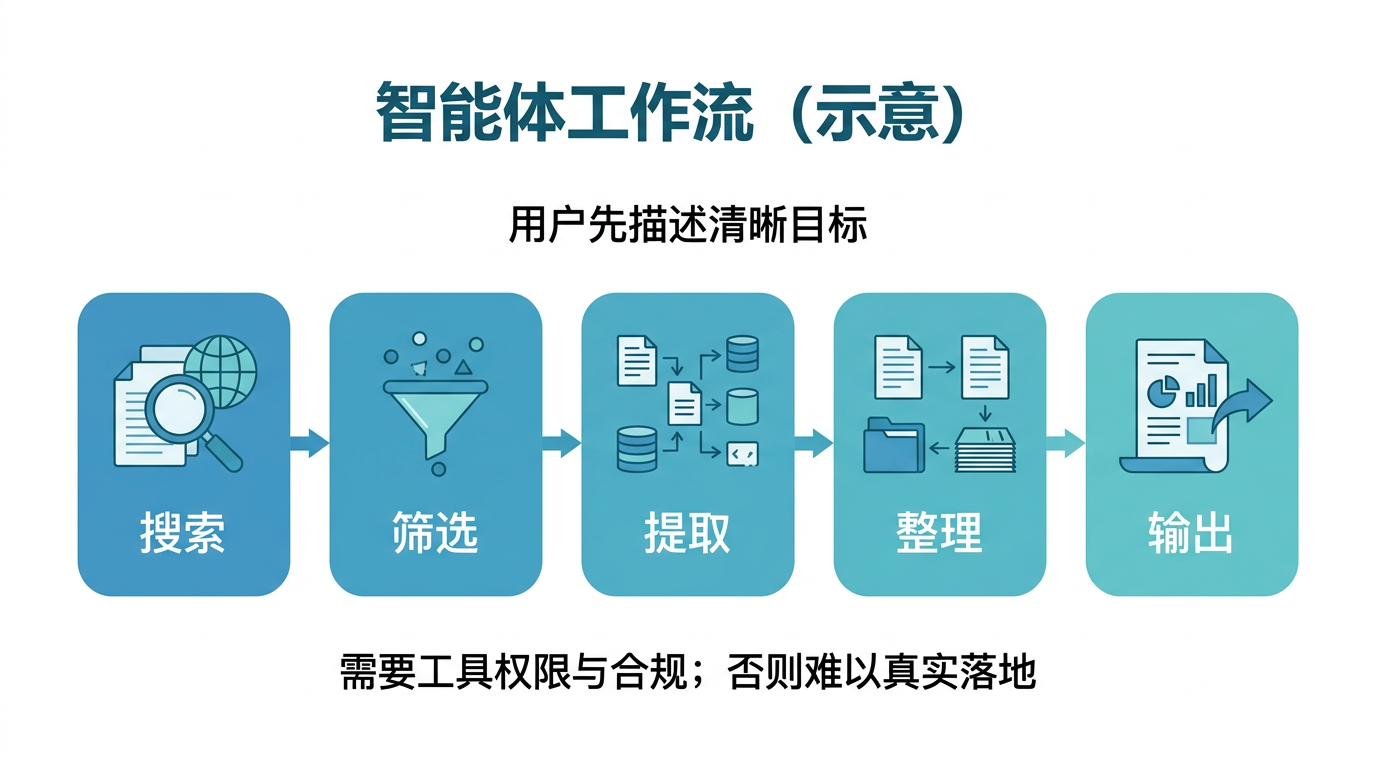
我们用一个具体例子来看区别。假设你需要"整理一份关于二甲双胍最新研究的文献综述"。
一个医院里的类比
普通对话 vs 智能体
普通对话就像你带一个什么都要问你的实习生——"下一步做什么?""这个怎么处理?"每一步都要你来指挥。
智能体就像你交代一个靠谱的住院总——"这个病人的出院准备你来负责"。他知道要做什么、怎么协调、遇到问题先自行判断再汇报。
现阶段你需要知道的:Agent 能力已经存在,很多工具已经在用。但你不需要现在就学会如何搭建自己的 Agent——那是 L3 智能体平台入门那节课要教的内容。在 L1 阶段,你只需要知道:AI 不只是一个"问答框",它可以变成一个能自动完成多步骤任务的"助手",这是后面课程要教你的能力。
AI 能力的边界
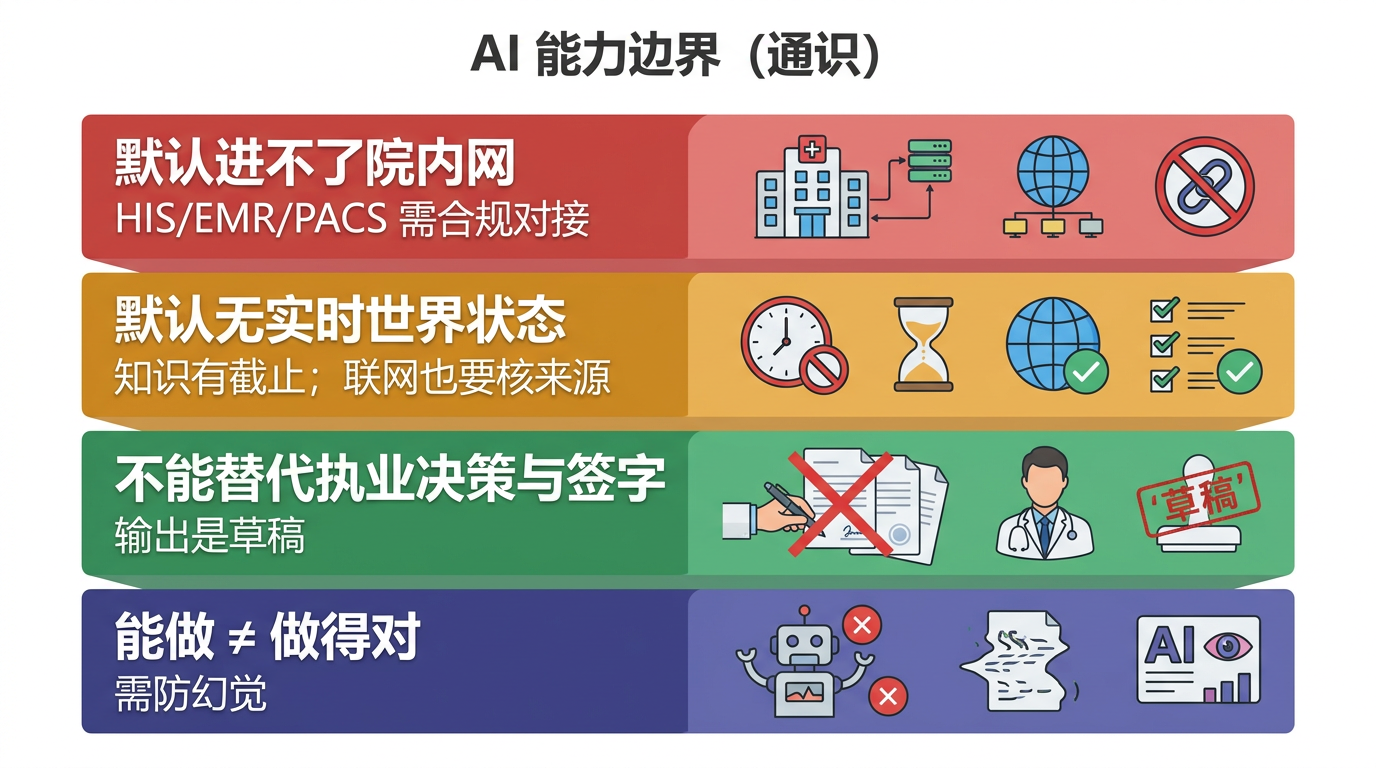
讲完了 AI "能做什么",同样重要的是知道它哪些能力默认不具备、哪些能力接了工具会增强、哪些事情再强也不该交给它拍板。
| 边界 | 说明 |
|---|---|
| 默认无法访问医院内网 | 通用 AI 默认看不到 HIS、EMR、PACS 等院内系统。只有做了合规审批、权限控制和系统对接后,它才可能安全读取相关数据 |
| 默认没有实时世界状态 | 裸模型有知识截止日期,不知道今天的新指南、实时价格或刚出的检查结果;如果接入联网搜索、数据库或 MCP,能力会明显增强,但来源仍要核实 |
| 无法替代执业决策 | AI 的输出不具备法律效力。所有涉及诊疗的决定,最终责任人永远是执业医师本人 |
| "能力" ≠ "可靠性" | AI 能生成一份看起来完美的诊疗方案,但内容可能包含幻觉(虚假信息)。能做 ≠ 做得对,必须人工验证 |
| 执行能力依赖权限和环境 | Agent 看起来像"自动干活",但前提是它拿到了合适的工具、权限和流程约束。没有这些,它就只是一个会说方案的助手,不是真正能落地的系统 |
记住这个原则
AI 的输出永远是"草稿",不是"定稿"。在医疗场景中,这个原则没有例外。
本节小结
你已经建立的认知
- 文字处理是 AI 最成熟的能力,L2 会带你深入实操
- 多模态让 AI 不止处理文字,还能看图、听音、画图,覆盖医疗场景中的多种信息形式
- 代码与工具原型也是现在很实用的一类能力,AI 已经能帮你快速搭出网页、脚本和小工具雏形
- 智能体 (Agent) 让 AI 从"被动回答"升级为"主动干活",L3 会教你如何搭建
- AI 有明确的能力边界——很多能力默认没有,需要联网、工具和权限;即便能力很强,输出仍需要验证
你现在建立的是一个全景预期——知道 AI 的能力版图有多大,也知道边界在哪里。接下来的 L1-4,我们要讲一个在实际使用前必须搞清楚的问题:合规。