AI 怎么工作的?
先做一个游戏
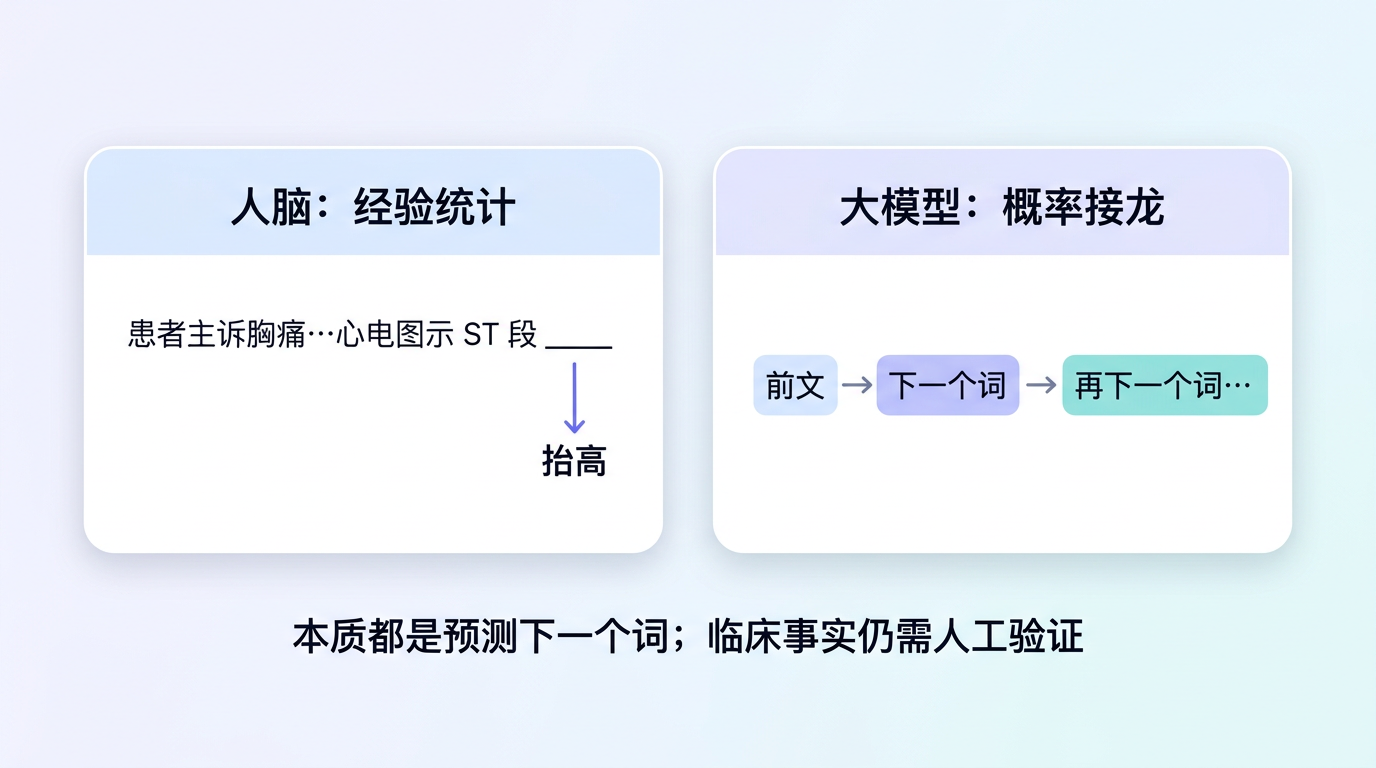
在解释 AI 怎么工作之前,我们先玩一个填空游戏。
文字接龙游戏
请你看这句话,在心里填上空缺的部分:
你是不是脱口而出了"抬高"?
恭喜你——你刚才做的事情,和 AI 做的事情,在本质上完全一样。
你能填出"抬高",是因为你在多年的医学学习和临床工作中,无数次看到过"ST 段"后面跟着"抬高"这个词。你的大脑根据经验和统计规律,预测了最可能出现的下一个词。
AI 做的是同样的事——只不过规模和速度远超人类:
下一个 Token 预测(Next Token Prediction)
AI 大模型的核心工作机制可以概括为一句话:根据前面所有的文字,预测下一个最可能出现的文字片段。
- 你看过几千份病历 → AI "读过" 数万亿字的文本
- 你在 1 秒内完成判断 → AI 在毫秒内完成计算
- 你的预测基于临床直觉 → AI 的预测基于数学概率
它一次只生成一个词(或词的一部分),然后把这个词加到前文中,继续预测下一个。如此反复,就"写"出了你看到的那一大段回答。
Token:AI 眼中的文字
我们刚才提到了"下一个 Token 预测"——这里有一个新名词:Token。
Token 是 AI 处理文字的最小单位。它不完全等于一个字或一个词,而是 AI 自己的"切词"方式:
| 原始文本 | 大约 Token 数 | 说明 |
|---|---|---|
| 糖尿病 | 2–3 个 | 中文每个字通常 1–2 个 Token |
| Diabetes | 1–2 个 | 常见英文单词通常是 1 个 Token |
| 一份完整病历 | 约 500–2000 个 | 取决于长度和语言 |
| 一篇论文摘要 | 约 200–400 个 | 英文比中文更"省 Token" |
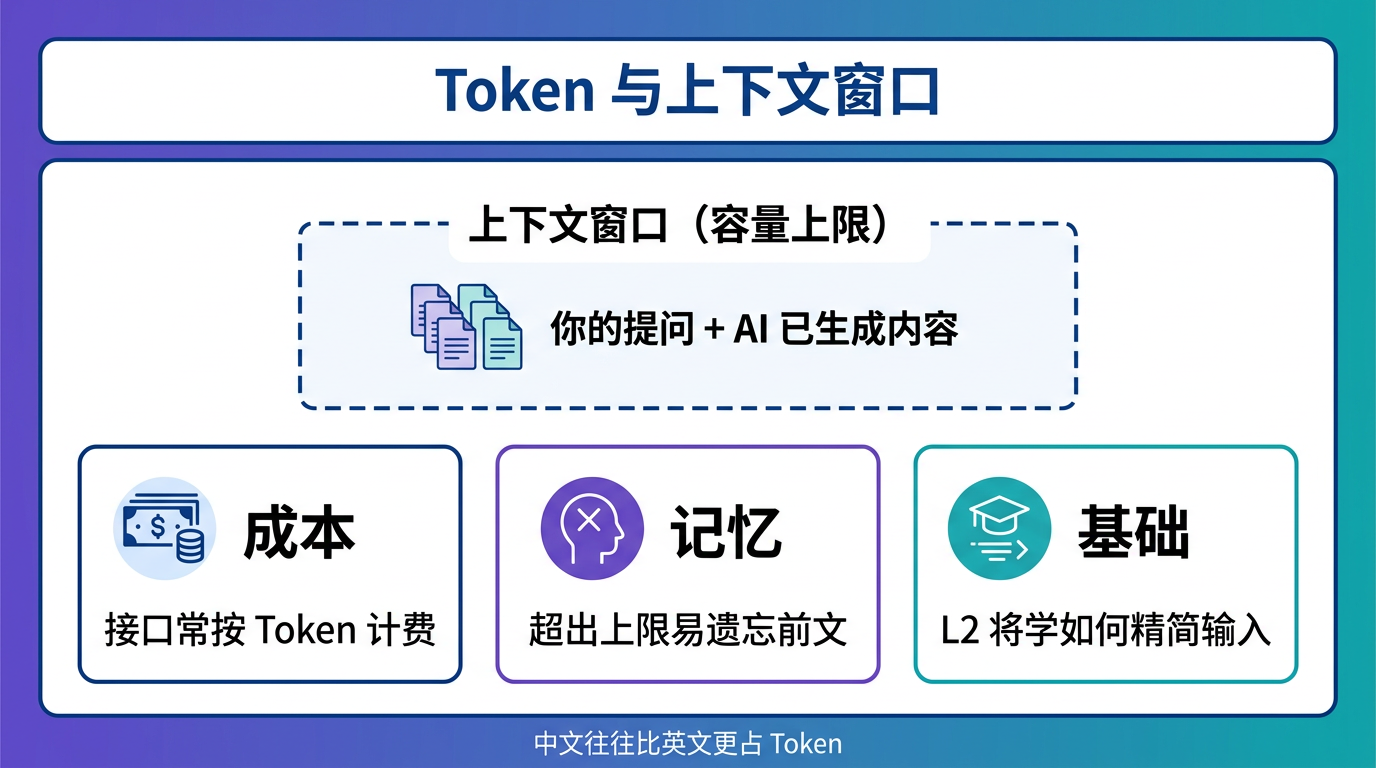
为什么你需要知道 Token 这个概念?因为它直接关系到三件事:
Token 的三重意义
- Token 常常关系到成本——在模型接口和很多专业工具里,Token 会直接影响费用;对普通用户来说,它至少会影响速度、上下文容量和产品成本。
- Token = 记忆容量——AI 一次对话能处理的 Token 数量是有限的,这叫做上下文窗口(Context Window)。超过了,AI 就会"忘掉"前面的内容。
- Token = 后续技能的基础——在 L2 课程中,你会学到如何通过控制输入的 Token 来优化 AI 的输出质量。
幻觉:最需要了解的概念
如果整个 L1 只能记住一个概念,就记住这个——幻觉(Hallucination)。
幻觉:AI 生成的内容看起来流畅合理,但实际上是错误的、编造的、或无中生有的。
医疗场景中的幻觉有多危险?
看看这些真实会发生的例子:
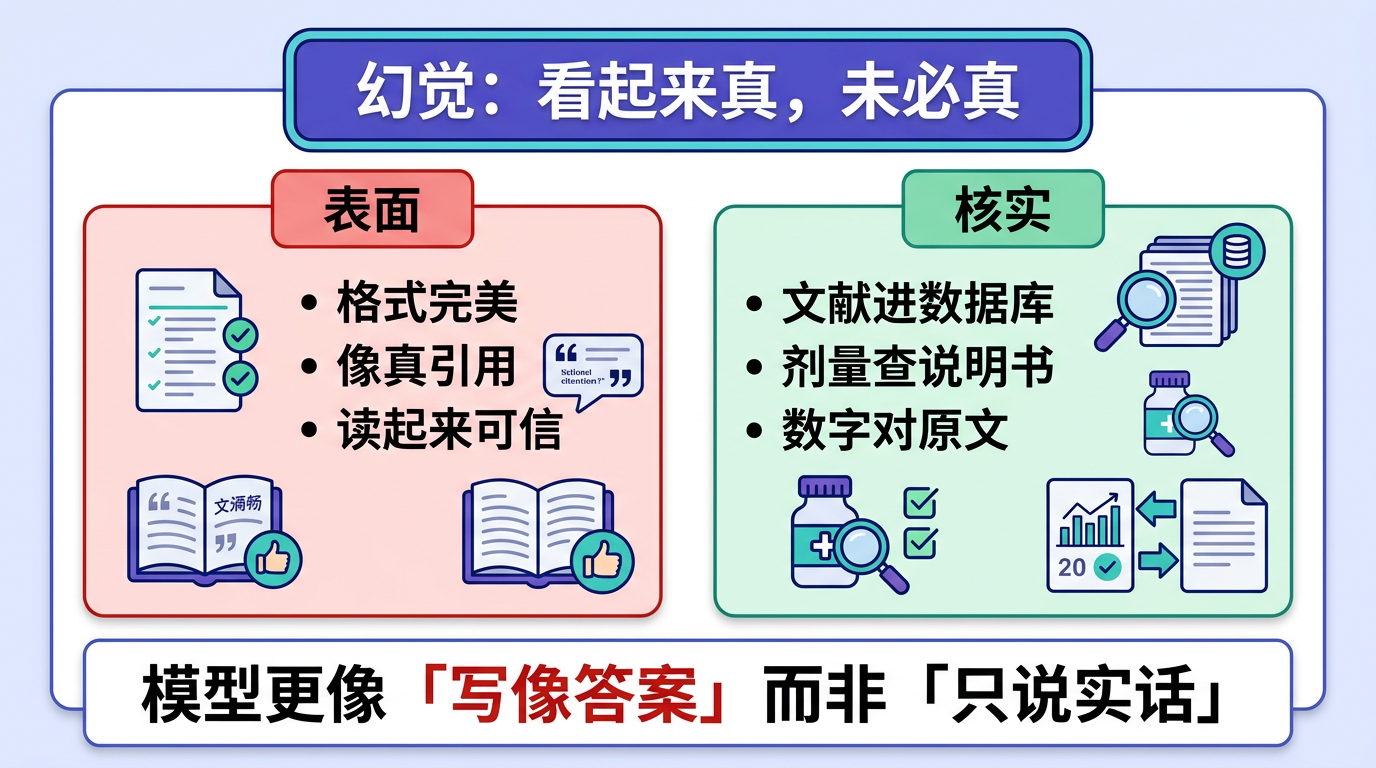
幻觉的典型表现
- 虚构文献引用——AI 给你引用了一篇论文,作者名、期刊名、年份都有,但这篇论文根本不存在。
- 混合正确与错误信息——一段关于某药物的说明,90% 是对的,但剂量写错了,或者把禁忌症搞混了。
- 伪造精确细节——AI 引用了"某指南第 47 页",但那份指南根本没有那一页,或那页讲的完全不是那个内容。
为什么 AI 会产生幻觉?
核心原因其实很简单:
AI 的目标是"生成听起来合理的文字",而不是"只说有把握的话"。
它的训练目标是让生成的文本在统计上"像"训练数据中的文本。当它遇到不确定的内容时,默认更倾向于继续生成一个看起来像答案的回答,而不是可靠地表达"我不知道"。这就是为什么没有校验机制时,幻觉会频繁出现。
最危险的是:你分不清真假
试着看下面这两条文献引用,判断哪个是真的:
Zhang, L., Wang, H., & Chen, Y. (2023). "Artificial Intelligence in Clinical Decision Support: A Systematic Review and Meta-Analysis." The Lancet Digital Health, 5(8), e512–e523.
Liu, M., Thompson, R., & Patel, S. (2024). "Large Language Models for Medical Diagnosis: Opportunities and Challenges." Nature Medicine, 30(2), 234–241.
这两条引用看起来都非常真实——格式规范、作者名合理、期刊是顶刊。但它们都是 AI 可能编造出来的。在实际使用中,AI 生成的引用看起来和真实引用几乎无法区分,唯一的办法是去数据库验证。
应对幻觉的策略
| 策略 | 具体做法 |
|---|---|
| 始终验证 | AI 给出的任何事实性内容(药物剂量、文献引用、指南内容),都要去权威来源交叉验证 |
| 要求引用来源 | 在提问时加上"请注明出处",虽然不能完全杜绝幻觉,但能提供验证线索 |
| 警惕"完美"答案 | 如果 AI 的回答格式完美、细节丰富、看起来毫无瑕疵——反而要更小心,因为真实世界很少这么"完美" |
| 使用外部工具辅助 | 通过 MCP 等方式让 AI 连接到真实数据源(这是 L3 的内容),从根源减少幻觉 |
温度:AI 回答的"随机性旋钮"
你可能注意到一个现象:同一个问题问 AI 两次,得到的回答可能不一样。有时候差别不大,有时候差别很大。
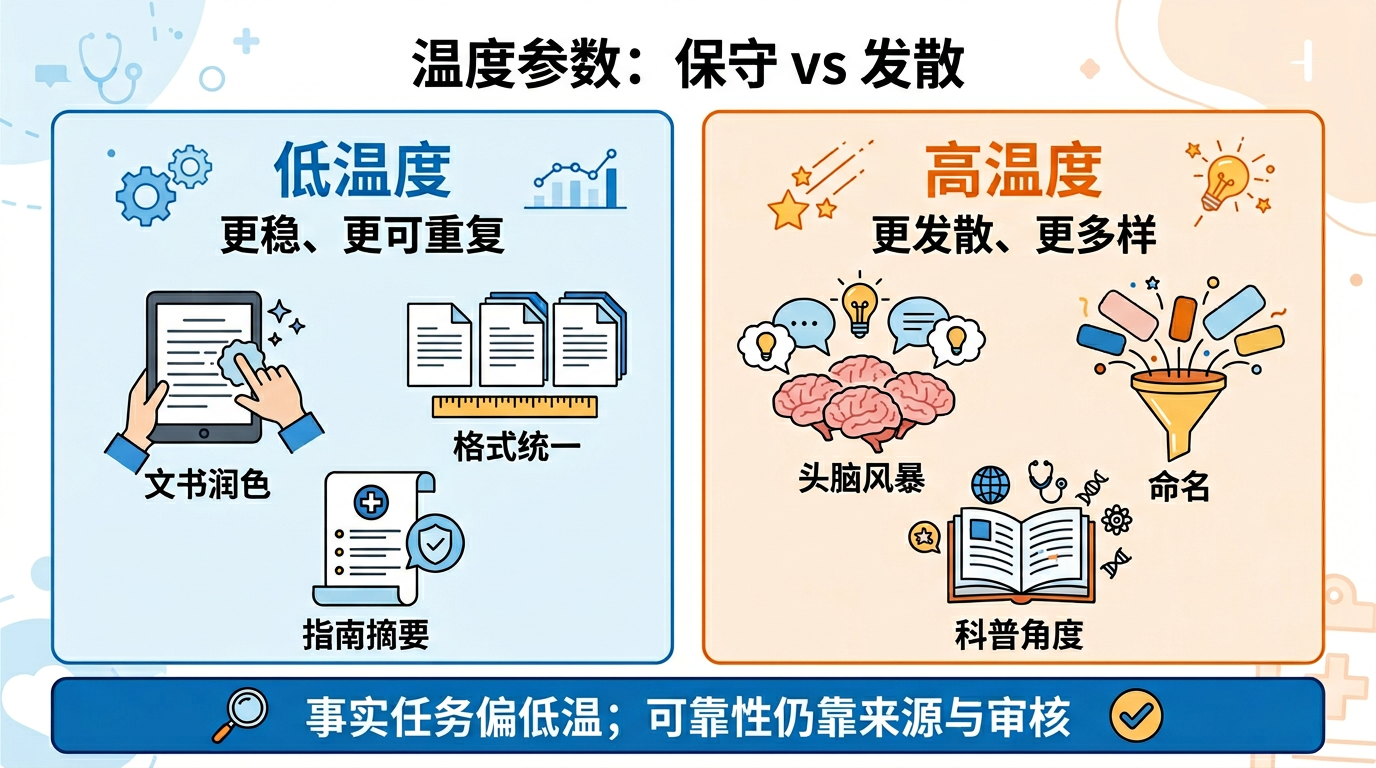
这是因为 AI 在预测下一个 Token 时,不是总选概率最高的那个——它会在多个候选里按概率抽样。控制这种"保守还是发散"倾向的参数,叫做温度(Temperature)。
保守、稳定、可重复
回答更稳定、更容易复现。适合事实整理、格式统一、病历润色、指南摘要这类希望结果尽量一致的场景。
创意、多样、不可预测
回答更发散、更有探索性。适合头脑风暴、命名、科普表达和多方案发想,但不适合把它当成事实正确性的保证。
温度的类比
想象你在做选择题。低温度更像"优先选最稳妥的答案",高温度更像"允许自己多想几个可能性"。
在医疗场景里,涉及事实、文书和建议时通常更适合用更稳的设置;但真正决定可靠性的,仍然是来源、工具接入和人工验证,不是温度一个参数。
本节小结
| 核心概念 | 一句话解释 | 临床意义 |
|---|---|---|
| 工作原理 | 根据前文预测下一个词,一个接一个地"写"出答案 | AI 不是在"思考"或"搜索",而是在做统计预测 |
| Token | AI 处理文字的最小单位,决定上下文容量,也常常关系到速度与成本 | 输入太长会超出上下文窗口,导致 AI "遗忘" |
| 幻觉 | AI 生成看似合理但实际错误或虚构的内容 | 必须对每一条事实性内容进行验证,特别是药物和文献 |
| 温度 | 控制 AI 输出风格与稳定性的参数,低温更稳,高温更发散 | 事实任务更适合稳一点的设置,但可靠性仍主要靠验证与工具支持 |