上下文工程
你可能遇到过这种情况
你跟 AI 聊了很长一段对话,前面详细描述过一位患者的情况、用药方案、检查结果。然后你问了几个问题之后,又追问了一句"那这个患者的降压方案需不需要调整?"
AI 的回答:居然完全没提你前面说过的 CKD 3 期和 eGFR 数据——就好像失忆了一样,给了一段通用的降压建议。
这不是 AI 在偷懒,也不是它"不上心"。这是一个技术限制——而且是你学会管理之后能显著改善的技术限制。
上下文窗口:AI 的"工作桌面"
L1-2 我们讲过 token 的概念。这里要用到它了。
每个 AI 模型能"同时看到"的 token 总量是有限的,这个总量叫上下文窗口(context window)。
打个比方:
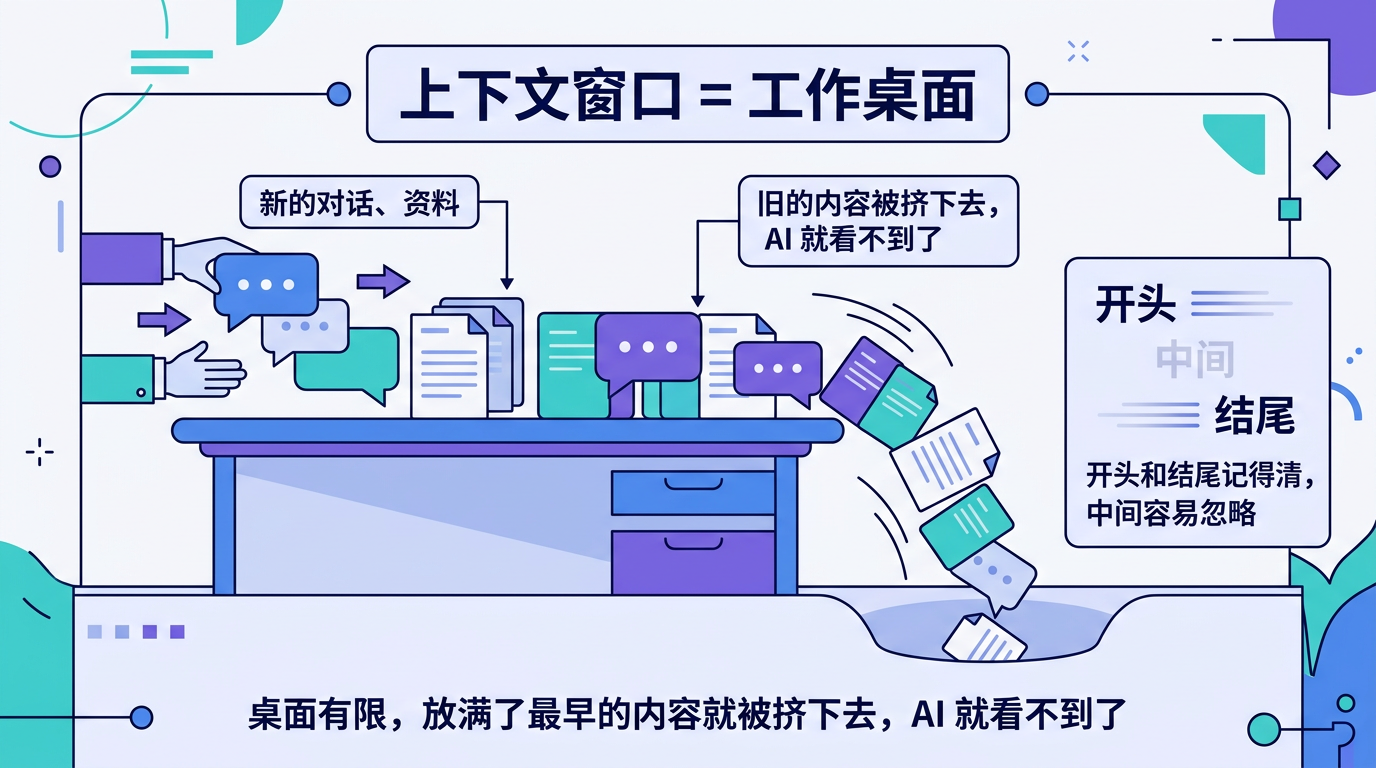
AI 的上下文窗口就像一张工作桌面。你跟它说的每一句话、它回复的每一段文字、你粘贴的每一份资料,都在往这张桌面上放东西。桌面的面积是固定的——放满了之后,最早放上去的东西就会被挤下去。
被"挤下去"的内容,AI 就看不到了。所以当对话太长的时候,前面的信息就丢了。
不同模型的"桌面大小"
| 模型 | 上下文窗口(大致) | 大概相当于多少字 |
|---|---|---|
| DeepSeek(标准版) | 64K token | 约 4-5 万字中文 |
| ChatGPT-4o | 128K token | 约 8-10 万字中文 |
| Kimi | 200K+ token | 约 15+ 万字中文 |
| Claude 3.5 | 200K token | 约 15+ 万字中文 |
注意:这些数字看起来很大,但实际使用中上下文会被你的输入 + AI 的回复 + 系统提示词一起占用。来回聊个 20 轮,加上粘贴的资料,很容易就满了。
而且还有一个隐藏的问题:即使没超出上下文窗口,AI 对"中间部分"的内容也会关注得比较少。学术上叫"lost in the middle"——开头和结尾的信息记得比较清楚,中间的容易被忽略。
所以不只是"桌面放不下"的问题,还有"桌面上东西太多、AI 找不到重点"的问题。
什么时候该开新对话
这是最简单但最实用的上下文管理技巧。
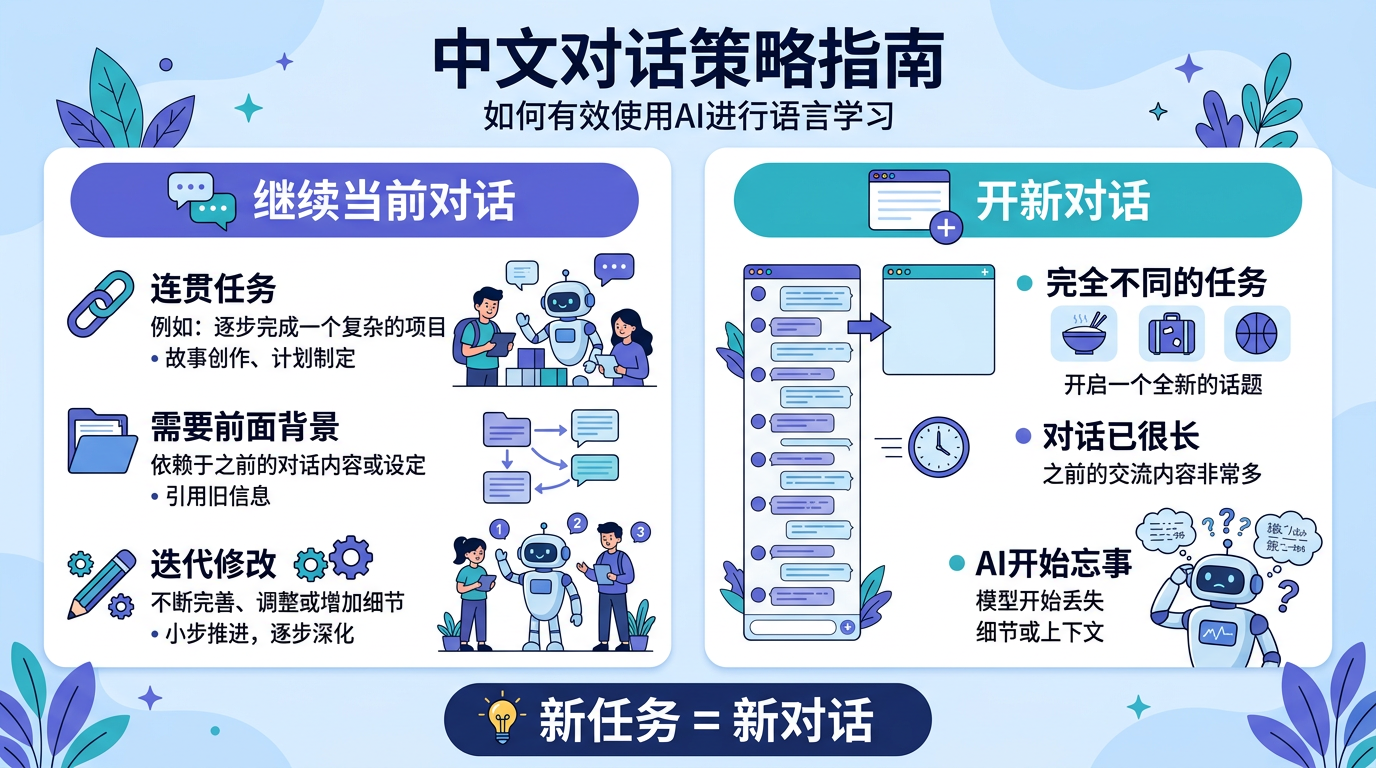
应该继续当前对话的情况
- 你在做一个连贯的任务,每一步都依赖前面的结果(比如"先整理病历 → 再分析用药 → 最后写讨论")
- 你需要 AI 记住你前面提供的背景信息
- 你在迭代修改一份输出("第二段重写""加一个表格")
应该开新对话的情况
- 你要开始一个完全不同的任务(刚才在整理病历,现在想查个药物信息)
- 对话已经很长了(超过 15-20 轮来回),你感觉 AI 开始"忘事"
- AI 的回答开始变得混乱——把不同患者的信息混在一起,或者不再遵循你之前给的指令
核心原则
新任务 = 新对话。不要在一个对话里什么都干。就像你不会在同一张纸上同时写两个患者的病历一样。
长对话的管理技巧
有些任务就是需要长对话怎么办?以下是三个实用技巧。
技巧一:摘要接力法
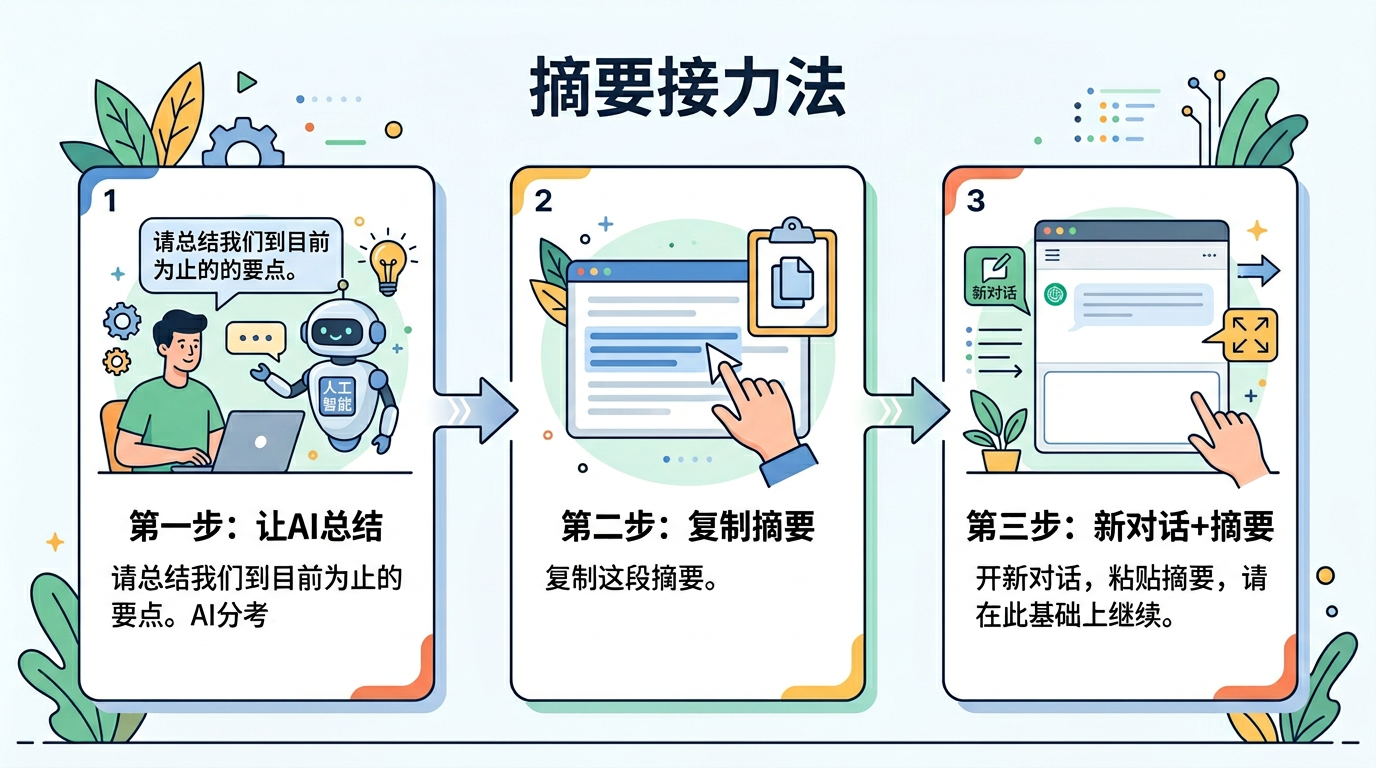
当一个对话快到极限时,不要硬聊下去,而是:
- 让 AI 先总结当前进展:"请总结一下我们到目前为止讨论的内容要点"
- 复制这段摘要
- 开一个新对话,把摘要粘贴进去:"以下是我们之前讨论的内容摘要,请在此基础上继续"
这就像值班换班时做交接——你不需要把所有细节都转述,但关键信息要交代清楚。
实操示例:摘要接力
假设你在一个长对话中整理了一份 5 种降压药的对比分析,现在要继续写结论。对话太长了,前面的信息开始丢失。
你可以说:
"请把我们到目前为止整理的 5 种降压药的对比要点总结成一个表格。"
AI 输出表格后,你复制这个表格到新对话:
"以下是 5 种降压药的对比表格(基于最新指南整理)。请基于此表格,为一位 60 岁合并糖尿病和 CKD3 期的患者写一段用药推荐和理由。"
技巧二:把重要信息放在开头或结尾
前面提到 AI 对"中间"内容关注度低。所以:
- 最关键的背景信息和指令放在提示词的开头
- 最具体的任务要求放在结尾
- 中间放参考资料和补充信息
就像写一篇论文的结构:摘要(最重要的结论)在最前面,方法和数据在中间,结论再强调一遍。
技巧三:在追问中重复关键信息
当你在一个长对话中追问新问题时,不要只写"那降压方案呢?",而是把关键背景信息再说一遍:
❌ "那降压方案需要调整吗?"
✅ "基于这位患者的 eGFR 38ml/min 和当前服用的氨氯地平 5mg qd,降压方案需要调整吗?"
多写几个字,效果差很多。你不确定 AI 是否还记得前面的信息时,就重复一下。重复不会有害,遗忘才会出问题。
给 AI "喂"背景资料
很多时候你需要让 AI 基于特定的资料来回答——一份指南、一段病历、一篇论文。这就是"喂"资料。
什么时候需要喂资料
- 你的问题涉及特定的指南或规范("按照 2024 版 CKD 管理指南,这个患者的血压目标值是多少?")
- 你需要 AI 基于特定文献回答("基于这篇论文的结果,SGLT2 抑制剂和 GLP-1 RA 哪个对肾脏保护效果更好?")
- 你需要 AI 处理你自己的文本("把这段查房记录整理成 SOAP 格式")
怎么喂
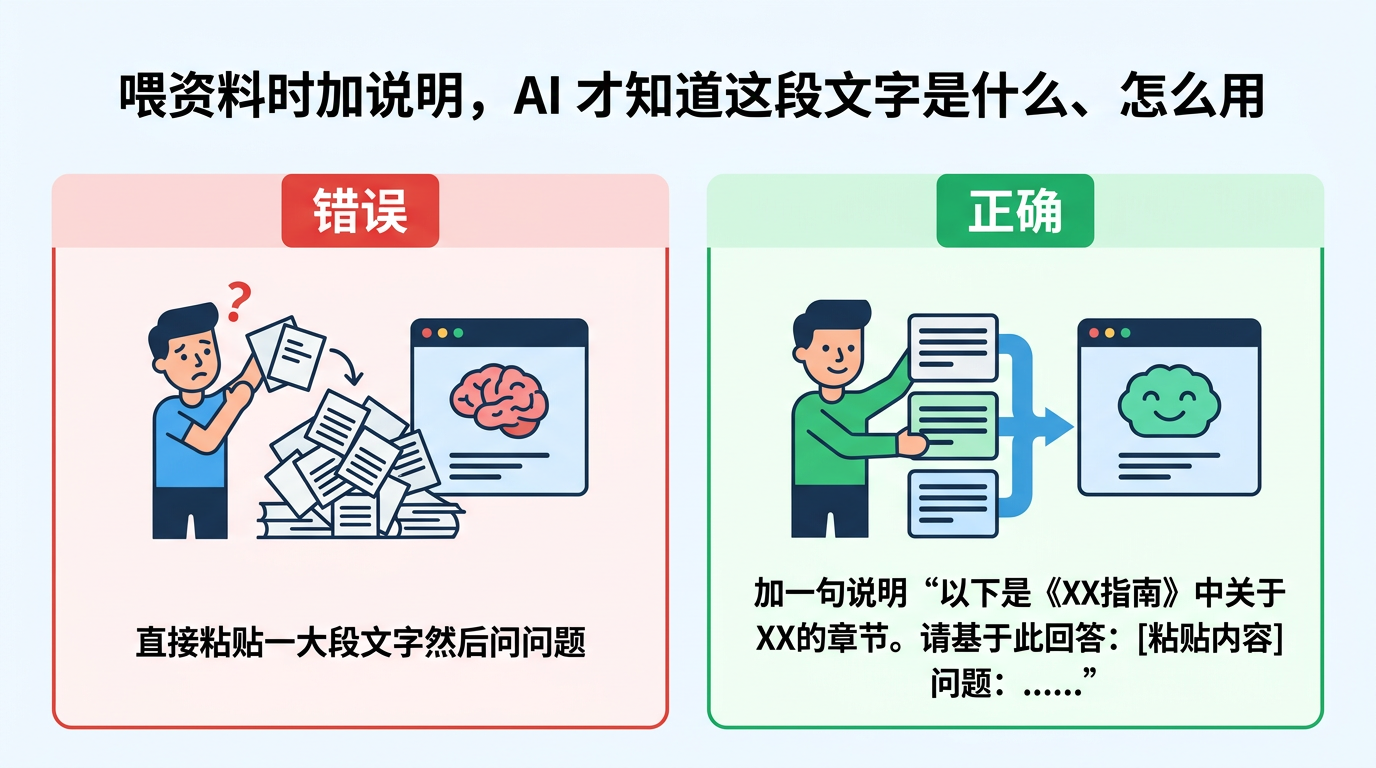
方式一:直接粘贴文本
最简单的方式。把相关内容复制粘贴到对话框里。适合短到中等长度的文本(几百到几千字)。
关键技巧:粘贴资料的时候,加一句说明。
❌ 直接粘贴一大段文字,然后问问题
✅ "以下是《2024 KDIGO CKD 管理指南》中关于降压目标的章节内容。请基于此回答后续问题:
[粘贴指南内容]
问题:对于糖尿病合并 CKD 3b 期的患者,收缩压目标应该是多少?"
那一句说明告诉了 AI 三件事:这段文字是什么(一份指南),是哪个部分(降压目标章节),你要它怎么用(基于此回答问题)。没有这句说明,AI 可能把你粘贴的内容当成你自己写的东西或者对话的一部分来处理。
方式二:上传文件
很多工具(ChatGPT、Kimi、豆包等)支持直接上传 PDF、Word 文档。适合较长的资料。
上传文件后同样要说清楚:
"我上传了一篇关于 SGLT2 抑制剂在心衰中应用的综述论文。请按以下结构提取信息:
1. 研究目的
2. 纳入的主要 RCT 及其结果
3. 作者的主要结论
4. 局限性"
喂资料的注意事项
1. 资料太长怎么办?
如果一份指南有几十页,不要全部粘贴。挑跟你问题相关的章节粘贴就行。全部粘贴进去反而会稀释重点,AI 更容易"找不到"关键信息。
2. 多份资料怎么处理?
如果需要 AI 参考多份资料,给每份资料加标签:
"以下是两份参考资料:
【资料一:2024 KDIGO 指南】
[粘贴内容]
【资料二:最新 Meta 分析结果】
[粘贴内容]
请综合两份资料回答以下问题……"
标签帮助 AI 区分不同资料的来源和性质,回答时也更容易标注"根据资料一……"
3. 记住上下文窗口的限制
粘贴的资料也占 token。一份 5000 字的指南大概占 7000-10000 个 token。如果你已经聊了很长的对话又粘贴了大段资料,很容易超出限制。
小贴士
如果要处理大段资料,建议在新对话中进行——把整个上下文窗口留给资料和你的问题。
自定义指令:一劳永逸的角色设定
有些信息你每次对话都要重复:你的职业、你的使用偏好、你希望的输出风格。每次都打一遍很烦。
大多数 AI 工具都提供了"自定义指令"或"记忆"功能,让你设定一次,之后每次对话自动生效。
在哪里设置
- 百小应:对话设置中支持自定义系统提示词
- ChatGPT:设置 → 个性化 → 自定义指令
- DeepSeek:对话设置 → 系统提示词
- 豆包:主页 → 我的设定
- Kimi:侧边栏 → 自定义设置
(具体位置可能随工具版本更新有变化,找不到的话直接在工具内搜索"自定义"或"指令")
设置什么
你可以把自己的基本信息和偏好写进去。比如一个内分泌科医生的自定义指令可以这样写:
关于我:我是一名三甲医院内分泌科的主治医师,主要负责糖尿病和甲状腺疾病的诊疗。我也参与研究生教学和临床研究。
我的偏好:
· 回答医学问题时请基于最新的循证证据,优先引用中国指南,其次国际指南
· 给出用药建议时请标注证据等级和来源
· 如果涉及不确定的内容,请明确标注"证据不足"或"需进一步验证"
· 我更喜欢结构化的输出格式(分点、表格),而不是长段落
· 使用中文回答
设置之后,你每次开新对话时 AI 就已经"知道"你是谁、你想要什么样的回答了。相当于每次都有一个了解你的助手在等你,而不是每次都面对一个陌生人。
自定义指令的局限
- 自定义指令也占上下文窗口(通常几百个 token),所以不要写太长
- 它是"默认设定",你可以在任何单次对话中用具体的指令覆盖它
- 不同工具的自定义指令功能成熟度不同——有些工具的效果很好,有些可能不太稳定
本节小结
| 概念 | 一句话记住 |
|---|---|
| 上下文窗口 | AI 的"工作桌面"是有限的,放满了就会挤掉旧内容 |
| 新对话的时机 | 新任务 = 新对话。不要什么都在一个对话里干 |
| 摘要接力 | 对话太长时让 AI 先总结,然后在新对话中用摘要继续 |
| 喂资料 | 粘贴内容时加一句说明:"以下是 XX,请基于此回答" |
| 自定义指令 | 把你的身份和偏好写进去,一次设定、每次生效 |